

My name isVincenzo Lomonacoand I’m aPostdoctoral Researcherat the University of Bologna where, in early 2019, I obtained my PhD in computer science working on “Continual Learning with Deep Architectures”in the effort of making current AI systems more autonomous and adaptive. Personally, I’ve always been fascinated and intrigued by the research insights coming out of the 15 years of Numenta research at the intersection of biological and machine intelligence. Now, as a visiting research scientist at Numenta, I’ve finally gotten the chance to go through all its fascinating research in much greater detail.
I soon realized that, given the broadness of the Numenta research scope (across both neuroscience and computer science), along with the substantial changes made over the years to both the general theory and its algorithmic implementations, it may not be really straightforward to quickly grasp the concepts around them from a pure machine learning perspective. This is why I decided to provide asingle-entry-point,easy-to-follow, andreasonably short guideto the HTM algorithm for people who have never been exposed to Numenta research but have a basic machine learning background.
Before delving into the details of the HTM algorithm and its similarities with state-of-the-art machine learning algorithms, it may be worth mentioning the theory that encompasses Numenta research efforts over the last 15 years: TheThousand Brains Theory of Intelligence. The Thousand Brains Theory is a biologically constrained theory of intelligence, built through reverse engineering the neocortex. HTM is the algorithmic implementation and empirical validation in silicon, of key components of the theory. So, let’s take a quick look at both of them below.
The Thousand Brains Theory of Intelligence
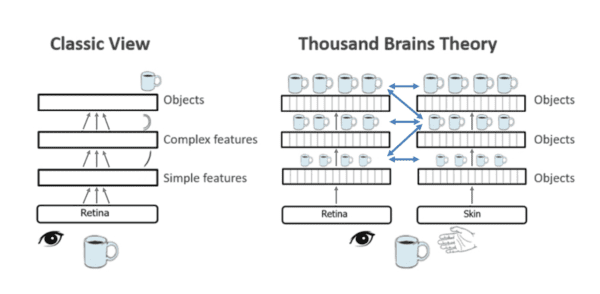
TheThousand Brains Theoryis the core model-based, sensory-motor framework of intelligence putting together the neuroscience research developed over the almost two decades of research atNumentaand theRedwood Neuroscience Institute (founded in 2002 by Jeff Hawkins). While backed by substantial anatomical and functional neurological evidence, it provides a unique interpretation of the high-level computation thought to happen throughout the neocortex and giving rise to intelligent behaviors.
In particular, the framework suggests mechanisms for how the cortex represents object compositionality, object behaviors and even high-level concepts from a basic functional unit tightly replicated across the cortical sheet: acortical column. It leads to the hypothesis that every cortical column learns complete models of objects. Unlike traditional hierarchical ideas in deep learning, where objects are learned only at the top, the theory proposes that there are many models of each object distributed throughout the neocortex (hence the name of the theory).
If you want to learn more about the theory I suggest starting from the recent 2019Frontiers in Neural Circuitspaper “A Framework for Intelligence and Cortical Function Based on Grid Cells in the Neocortex”. I think the temporal, location-based and compositional nature of the framework, along with its disruptive rethinking of multi-modal integration and hierarchy, may provide invaluable insights for future machine learning developments.
Further reads and interesting resources related to the theory I really enjoyed:
- Jeff Hawkins’ Human Brain Project Open Day keynote
- Lex Fridman’s Podcast with Jeff Hawkins
- Two papers that include detailed network models about core components of the theory: “A Theory of How Columns in the Neocortex Enable Learning the Structure of the World”and “Locations in the Neocortex: A Theory of Sensorimotor Object Recognition Using Cortical Grid Cells”
- A Comprehensive List of Numenta Papers
The HTM Algorithm
The HTM algorithm is based on the well understood principles and core building blocks of theThousand Brains Theory. In particular, it focuses on three main properties:sequence learning,continual learningandsparse distributed representations.
Even if substantially different in terms of algorithmic approach and learning rule, at a higher level, it may be possible to associateHierarchical Temporal MemoriestoRecurrent Neural Networks. In fact, HTMs are particularly suited for sequence learning modeling as the latest RNNs incarnation such asLSTMsorGRUs .
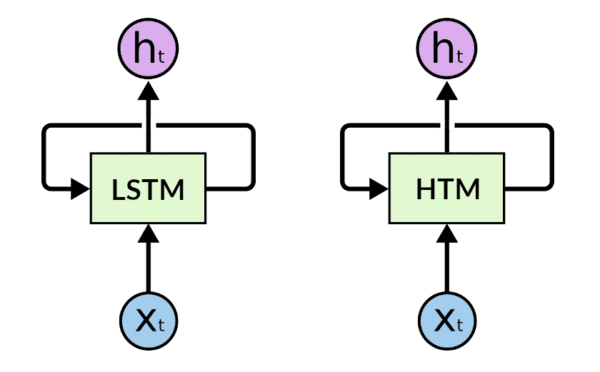
However, the main differences with RNNs are:i)HTMs have a more complex neuron model;ii)HTMs do not employ back-propagation but a simple (and local) unsupervisedhebbian-learning rule;iii)HTMs are based on very sparse activations and neuron connectivity;iv)HTMs are based on binary units and weights. On one hand this means that HTMs can be implemented in an incredibly efficient way. On the other hand, in the case of highly dimensional input patterns, they may strive to solve thecredit-assignment problemif stacked in a multi-layer fashion asMulti-Layer LSTMsorConvolutional LSTMs.
Nevertheless, the HTM algorithm supportsby designseveral properties every learning algorithm should possess:
- Sequence learningBeing able to model temporally correlated patterns represents a key property of intelligence, as it gives both biological and artificial systems the essential ability to predict the future. It answers the basic question “what will happen next?” based on what it has seen before. Every machine learning algorithm should be able to provide valuable predictions not just based on static spatial information but also grounding it in time.
- High-order predictions
Real-world sequences contain contextual dependencies that span multiple time steps, hence the ability to make high-order predictions becomes fundamental. The term “order” refers to Markov order, specifically the minimum number of previous time steps the algorithm needs to consider in order to make accurate predictions. An ideal algorithm should learn the order automatically and efficiently. - Multiple simultaneous predictions
For a given temporal context, there could be multiple possible future outcomes. With real-world data, it is often insufficient to only consider the single best prediction when information is ambiguous. A good sequence learning algorithm should be able to makemultiple predictions simultaneouslyand evaluate the likelihood of each prediction online. This requires the algorithm to output a distribution of possible future outcomes. - Continual Learning
Continuous data streams often have changing statistics. As a result, the algorithm needs to continuously learn from the data streams and rapidly adapt to changes. This property is important for processing continuous real-time perceptual streams, but has not been well studied in machine learning, especially without storing and reprocessing previously encountered data. - Online learning
For real-time data streams, it is much more valuable if the algorithm can predict and learn new patterns on-the-fly without the need to store entire sequences or batch several sequences together as it normally happens when training gradient-based recurrent neural networks. The ideal sequence learning algorithm should be able to learn from one pattern at a time to improve efficiency and response time as the natural stream unfolds. - Noise robustness and fault tolerance
Real world sequence learning deals with noisy data sources where sensor noise, data transmission errors and inherent device limitations frequently result in inaccurate or missing data. A good sequence learning algorithm should exhibit robustness to noise in the inputs. - No hyperparameter tuning
Learning in the cortex is extremely robust for a wide range of problems. In contrast, most machine-learning algorithms require optimizing a set of hyperparameters for each task. It typically involves searching through a manually specified subset of the hyperparameter space, guided by performance metrics on a cross-validation dataset. Hyperparameter tuning presents a major challenge for applications that require a high degree of automation, like data stream mining. An ideal algorithm should have acceptable performance on a wide range of problems without any task-specific hyperparameter tuning.
While *** especially 4, 5, 6, and 7 areextremely difficultto satisfy in a state-of-the-art recurrent neural network, HTM naturally excels on those.
HTM from Zero to Hero!
Having given a brief contextualization to the HTM algorithm, in this section I’ll try to provide a quick curriculum for anyone interested in learning more about it, starting from scratch. In particular, I’ll cover two main parts: 1) the main algorithm implementation and details; 2) its practical application to real-world sequence learning problems. Some of the detailed algorithms as of 2016 are described inBiological And Machine Intelligence (BAMI). More recent work is available as papers. Note that the terminology ofHTM Theoryin BAMI has changed toThe Thousand Brains Theory.
HTM Algorithm
- HTM Overview(BAMI Book Chapter)
This short chapter introduces the main design principles and biological motivations behind the HTM algorithm. - Sparse Distributed Representations
- Sparse Distributed Representations(BAMI book Chapter)
Sparse Distributed Representations (SDRs) constitute the fundamental data structure in HTM systems. In this chapter several interesting and useful mathematical properties of SDRs are discussed. Neuroscience evidence of sparse representations in the brain are also discussed. - Properties of Sparse Distributed Representations and their Application to Hierarchical Temporal Memory(paper)
This work is a short and self-contained summary of the mathematical properties of SDRs, independently of the HTM algorithm itself. - How Can We Be So Dense? The Benefits of Using Highly Sparse Representations(paper)
What about the relationship of SDRs with sparsity and standard deep neural nets trained with gradient descent? This paper discusses these interesting junction issues. Moreover, it proposes a sparsification approach (of both weights and activations with boosting) to close the gap between SDRs and Neural Nets activations volumes. Thorough experiments show nice robustness properties and resistance to noise similar to the ones obtainable with binary SDRs in the HTM algorithm.
- Sparse Distributed Representations(BAMI book Chapter)
- Spatial Pooling(BAMI book Chapter)
The Spatial Pooling algorithm is the inner HTM module in charge of the feed-forward pattern propagation and recognition. - Temporal Memory(BAMI book Chapter)
The Temporal Memory algorithm is the inner HTM module in charge of the recurrent connection and SDRs sequence modeling. - Continuous Online Sequence Learning with an Unsupervised Neural Network Model(paper)
I think this paper would be the perfect read to close the loop on the HTM algorithm. It summarizes with a clear and compact notation the HTM algorithm and evaluates it on reasonably complex sequence learning problems. In the proposed experiments, the performance of HTM is incredibly aligned with LSTM, still considered the go-to algorithm for sequence learning problems. However, HTM has many more advantages considering the other important properties it fulfills as previously pointed out.
HTM for Practical Applications
- Encoding Data for HTM Systems(paper)
In order to apply the HTM algorithm to your own problem, it may be not straightforward to understand the concept of SDRs encoding and decoding coming from a ML background. This paper explains how to preprocess categorical and numerical data in order to create SDRs to feed into the HTM algorithm. - NuPIC (HTM Toolkit)
The HTM algorithm has been implemented inseveral programming languages by the community, but the official software toolkit for building and using HTM models, NuPIC, is written in Python. Take a look at thequick start, the walkthrough jupyternotebook, or theother software resourcesmade available by the Numenta research team if you want to try the algorithm yourself in a matter of minutes! - Real-Time Anomaly Detection
- Evaluating Real-time Anomaly Detection Algorithms: the Numenta Anomaly Benchmark(paper)
This paper introduced a newly designed benchmark (NAB) for real-time anomaly detection and preemptive maintenance, showing how you can apply HTMs to this problem in an efficient and effective way. It also proposes an original and more challenging scoring function to give more credit to faster anomaly predictions. It seems the community has already embraced the benchmark, using it quite extensively in this application context. - Unsupervised Real-time Anomaly Detection for Streaming Data(paper
This work presents another interesting application of HTM in the context of anomaly detection and using the NAB benchmark, but with a more in depth analysis and extended comparison with other state-of-the-art algorithms.
- Evaluating Real-time Anomaly Detection Algorithms: the Numenta Anomaly Benchmark(paper)
Finally , for a more in depth understanding of the HTM algorithm you may also want to check:
- HTM Forum: a place for Q & As and discussion around the HTM algorithm.
- HTM School: a video series on HTM starting from scratch if you prefer watching rather than reading.
Conclusions
In this blog post I tried to contextualize theHTMalgorithm within the Numenta research efforts and to help AI & machine learning researchers learn more quickly about HTMs with a short and tailored curriculum. However, there’s much more material you can explore on theNumenta community websiteor its social platforms, including podcasts and live stream recordings of open research meetings, so I invite you to check them out in case you are as interested in these ideas as I am!
As the deep learning hype is reaching its saddle point and AI researchers are more promptly starting to look to new original approaches, it seems Numenta is uniquely positioned to lead the path towards the next wave of Neuroscience-Inspired AI research. Despite the relative youth of the HTM algorithm, early comparative results with state-of-the-art sequence learning algorithms show how a neuroscience grounded theory of intelligence may inform and guide the development of future AI systems endowed with increasingly intelligent behavio urs.



GIPHY App Key not set. Please check settings