
Just-in-time compilation (JIT) is a beautiful thing, and Java leads the industry. But unlike C2, which compiles your class files with optimizations for a particular OS (mac), ISA (x 86 _ 64), and Architecture (Intel Broadwell), JVM distributions themselves are compiledonlyfor OS and ISA. This enables portability while reducing the number of build combinations for vendors.
The native code running alongide your Java app, like C1 and the garbage collector, is significant. The question is, if we compile OpenJDK for our own architecture, will app throughput improve in a significant way? The answer appears to be yes.
Building the JDK
We’ll be comparingAdoptOpenJDK‘s Mac OpenJDK 13, and a custom-built OpenJDK 13. Both are the same build, 33. These are my build instructions:
- Clone the OpenJDKgit mirror
- Check out release33
- Run
bash configureaccording tothe doc:
bash configure- with-jvm-variants=server- with-jvm-features=link-time-opt- with-extra-cflags='- Ofast -march=native -mtune=broadwell -funroll-loops -fomit-frame-pointer '- with-extra-cxxflags='- Ofast -march=native -mtune=broadwell -funroll-loops -fomit-frame-pointer 'We configure with the standard (server) varient, which includes jvm-features likeG1GCand (C2) . Additionally,link-time-optis added to the build. I could not find any documentation on this feature, but presumably it performs link time optimization, which should improve performance. Now lets consider the C and C compile flags.
- Ofastis the highest optimization profile available in clang and gcc, and comes with a few drawbacks. Binary size may be larger, and floating-point semantics are relaxed. One may replace this profile with- O3, which keeps strict fp conformance, or-O2, which also maintains binary size. I have tested with both Ofast and O3, and haven’t experienced problems with either. But your mileage may vary.
- march=nativeand- mtune=broadwelltell the compiler to optimize for your architecture. One would think given the compiler documentation thatmarchimpliesmtune, but this isapparently not the case.
- funroll-loopsensures that loops are unrolled. Loop unrolling should be especially performant, sincemarchis specified. Loop unrolling is included with clang’s- O3and up, but must be manually set for gcc.
- fomit-frame- pointerallows the compiler to omit frame pointers when possible, freeing a register. This could make debugging the JVM’s native code painful.
- Make the jdk with:
make images (CONF)=Macosx-x 86 _ 64 - server-releaseThe build takes only 15 minutes or so on my early 2015 macbook, even with optimizations enabled.
- Find the jdk in
build / macosx-x 86 _ 64 - server-release / images / jdk -bundled, append to PATH and run some tests!
Benchmarks
DaCapowas the first benchmark suite I ran.
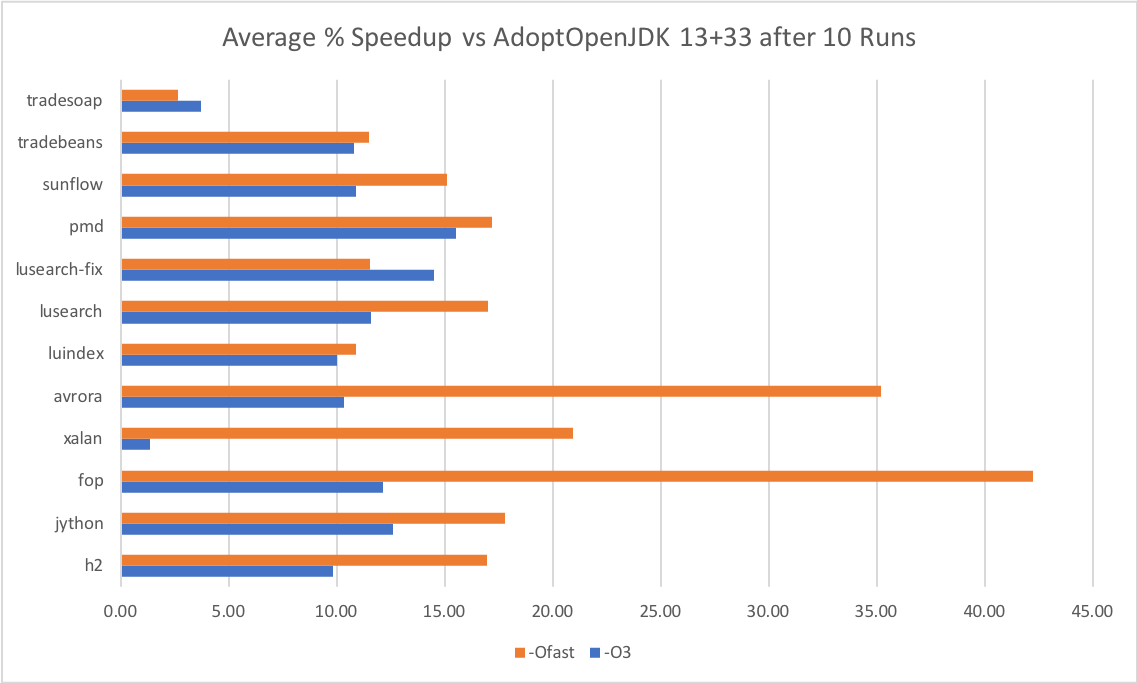
The optimized JDKs outperform in every case, with the avrora and fop benchmarks gettingbigspeedups with-Ofast. Really curious as to why this is the case!
Next up I ran some benchmarks from theComputer Language Benchmarks Game.
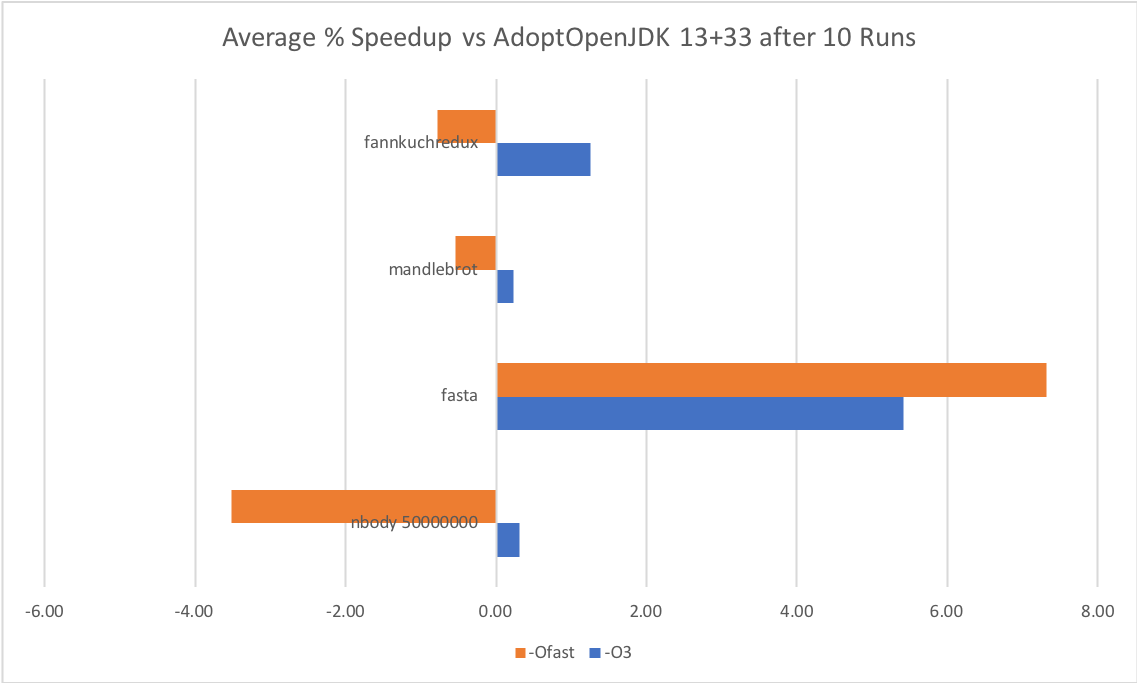
These I calculated withtime for i in {1 .. 10}; do java, and divided by 10. There was no significant difference between the JDKs. Unlike DaCapo, these benchmarks are not representative of normal workloads and should be given less value. For example, none of the benchmarks generate garbage or exercise JVM features other than C2. But at least we know that C2 and startup are not the benefactors of the optimizations!
Finally I executed some JMH microbenchmarks forNetty‘s HttpObjectEncoder:
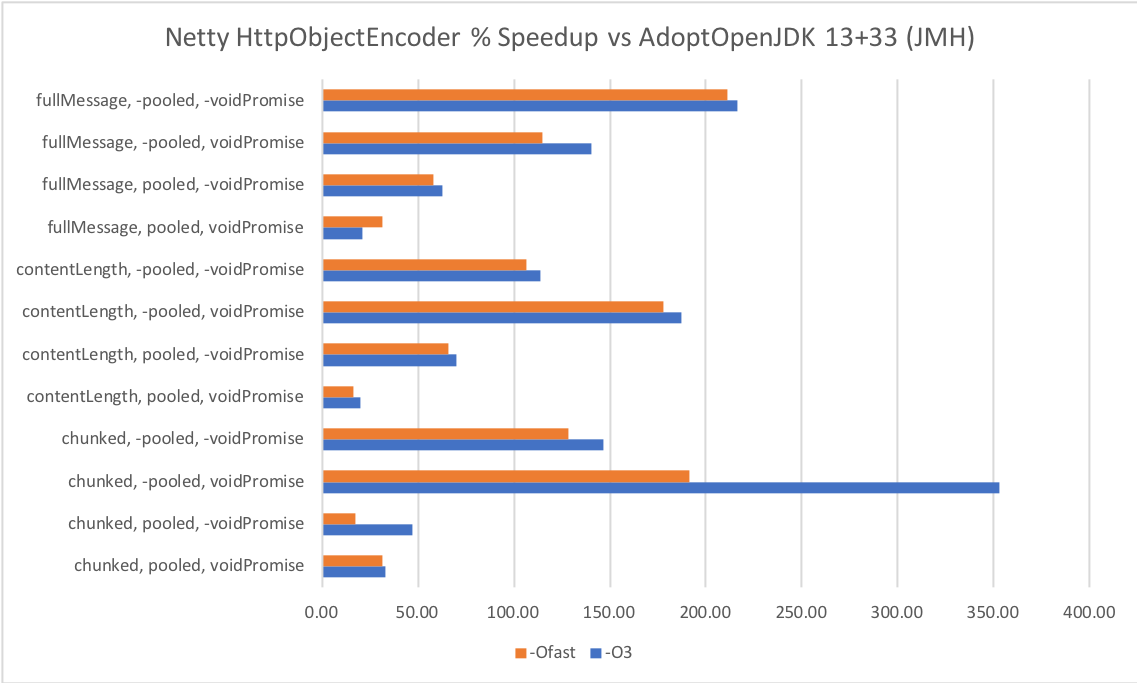
I chose this microbenchmark somewhat at random after looking at Netty’sExtensive collection. The speedup is massive in the case when allocation is not pooled, and void Promises are not returned, and still big otherwise. Of course, these methods are unlikely to dominate your application’s performance. There appears to be a glitch in the second chunked bench.
Note: Netty offersNative Transport… so if we could compilethisas well!
Other Compilers and OS
I also tried building withIntel’s Compiler, and patched the configure scripts to allow it. However, the build failed cryptically. I’d also be interested to see Linux results.
Summary
So, while you need to test with your own applications, it is clear that targeting the JDK to a specific architecture can provide significant throughput improvements. Coupled with the absolute ease of building new JDKs (Project Skarais awesome), developers of performance-critical Java applications should seriously consider building an optimized JDK, just the same as C / developers build optimized binaries.
Tables for Those Inclined



Modesty
I doubt my methodology is perfect, if not let me know!




GIPHY App Key not set. Please check settings