
In this tutorial, we will implement a Rust program that attempts to utilize 100% of the theoretical capacity of three relatively modern, mid-range CPUs. We’ll use an existing, highly efficientC implementationas a reference point to compare how our Rust program is doing. We start with a simple baseline solution of 3 nestedfor– loops, and keep improving on the baseline solution incrementally, implementing 8 versions in total, until the program is going so fast it can hardly go faster. We’ll approach the problem from the point of view of a C programmer who already knows how the reference implementation solves the problem, but is interested in an approach using the Rust language.
Writing a program that pushes the CPU to its limits requires some understanding of the underlying hardware, which sometimes means reading the output of a compiler and using low-level intrinsics. I encourage you to also study thereference implementationmaterials, or at least keep them close by as we will be referencing to those materials quite often. The reference materials explain many important concepts very clearly, with intuitive visualizations that show why each incremental improvement makes the hardware execute the program faster.
Note that most of the optimization tricks shown in this tutorial are merely Rust-adaptations of the original C solutions. Interestingly, this does not require as muchunsafe– blocks as one would initially assume. As we will see in this tutorial, safe Rust can be just as fast as a highly optimized C program.
The program
The program we will implement and improve on, is an Θ (n³) algorithm for a graph problem, which is described in more detailhereas the “shortcut problem”. All input will consist of square matrices containingnrows and columns of single precision floating point numbers. The reference implementations are all defined in functions calledstepand provide one baseline implementation with 7 incrementally improved versions ofstep. We will implement 8 differentstepfunctions in Rust, each aiming to reach the performance of its corresponding C implementation.
It is important to note that we assume the algorithm we are using is the best available algorithm for this task. The algorithm will stay the same inallimplementations, even though we will be heavily optimizing those implementations . In other words, the asymptotic time complexity will always remain at Θ (n³), but we will be doing everything we can to reduce the constant factors that affect the running time.
Incremental improvements
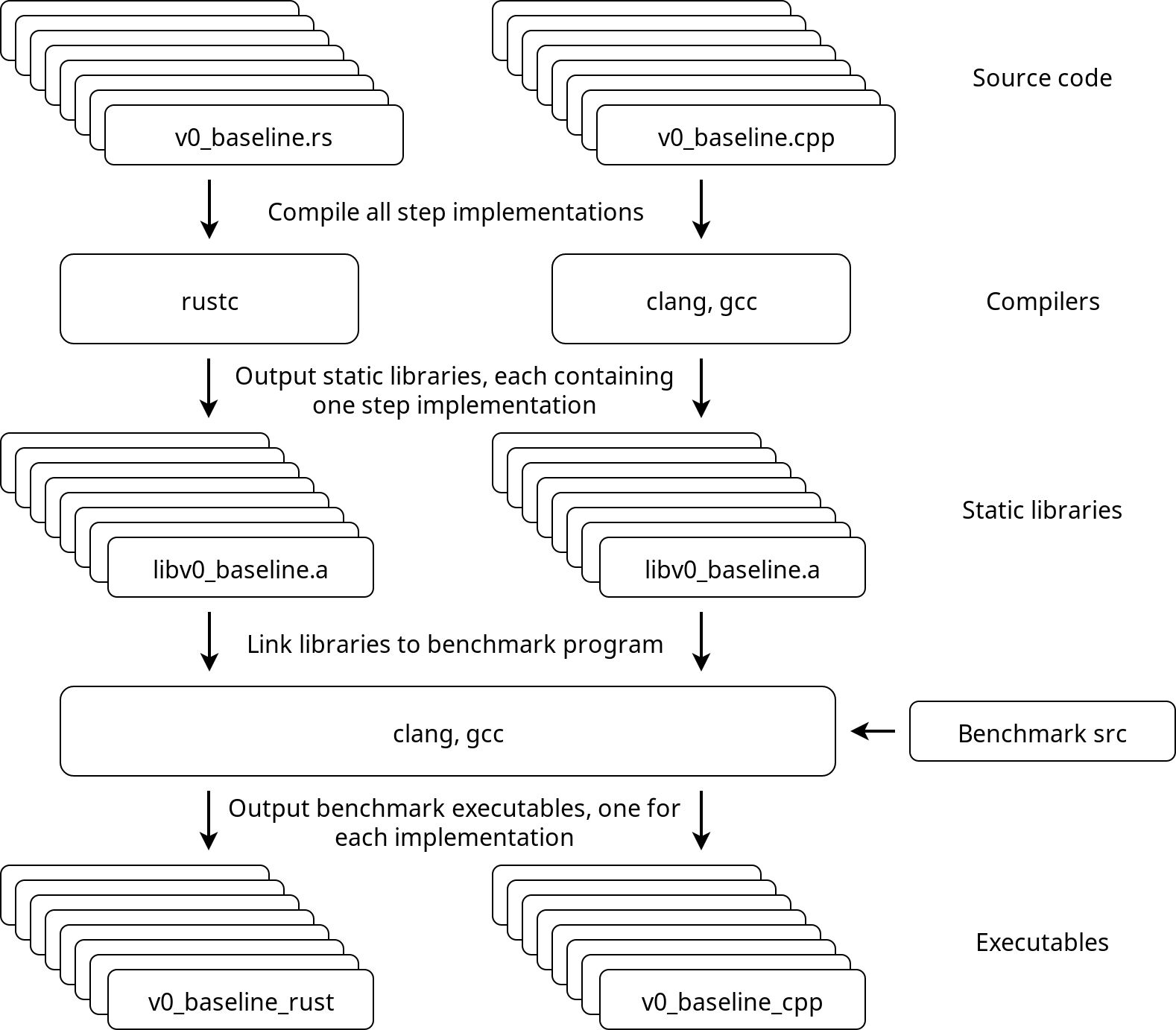
Here is a brief summary of all 8 versions of thestepfunction that we will be implementing. All implementations will be compiled as static libraries that provide a function calledstep, with C-language linkage. Those static libraries will be linked to thebenchmarking programthat generates the data consisting of random floats and callsstepwith the generated data, while recording the amount of time spent executing the function.
v0: Baseline
Simple solution with 3 nested for loops.
v1: Linear reading
Copy the input matrix and store its transpose inrow-major order, enabling a linear memory access pattern also for the columns of the input matrix.
v2: Instruction level parallelism
Break instruction dependency chains in the innermost loop, increasing instruction throughput due toinstruction level parallelism.
v3: SIMD
Pack all values of the input matrix, and its transpose, row-wise into SIMD vector types and useSIMD instructionsexplicitly, reducing the total amount of required instructions.
v4: Register Reuse
Read the input and its transpose in 3-row blocks of SIMD vectors and compute 9 results for each combination of vector pairs in the block, reducing the amount of required memory accesses.
V5: More register reuse
Reorder the input matrix and its transpose by packing the data into SIMD vectors vertically, instead of horizontally. Read the vertically ordered data row-wise in pairs of 2 vectors, create 4 different permutations from the SIMD vector elements and compute 8 results for each pair, further reducing the amount of required memory accesses.
v6 : Prefetch
Add prefetch hint instructions to take advantage of vacant CPU execution ports that are reserved for integer operations (since we are mostly using floating point arithmetic).
v7: Cache reuse
Add aZ-order curvememory access pattern and process input in multiple passes one vertical stripe at a time, slightly improving data locality from cache reuse.
Compilation infrastructure
Here’s an approximate overview of the benchmark program and how everything is tied together.



GIPHY App Key not set. Please check settings