

It’s been nearly 5 years since I dropped this old post about Splunk Gotchas. Okay, in fairness, I also covered SPL-based, path normalization in 2020 & bitmap-based hunting aka bitmap hunting here and here in 2024. Still… I thought it would be nice to re-visit this topic, because there is so much to talk about…
Now, I will cover a few gotchas here but before I do so, I want to state as follows: I am fully aware that out of all these presented, more are more, and few are less… known… after all I am still a SPL n00b, so you may already know it all. I don’t claim any of it is groundbreaking in any way, but hope it may still help someone…
Gotcha #1 – improving readability of file permissions
Let’s take a look at file permission values that we often get from logs f.ex. from sources like ossec (popular Host Intrusion Detection System/File Integrity Monitor). Its logs are a bit cryptic, but once you extract the preserved permission attributes for a given file (for simplicity, we assume 3 octets here that translate to a set of ‘R’, ‘W’, ‘X’ rights) into say oct1, oct2, oct3we can use the below loop to convert all these octets into actual string representation of the right:
| foreach oct* (
eval <<FIELD>>=replace(<<FIELD>>,"0","---")
| eval <<FIELD>>=replace(<<FIELD>>,"1","--X")
| eval <<FIELD>>=replace(<<FIELD>>,"2","-W-")
| eval <<FIELD>>=replace(<<FIELD>>,"3","-WX")
| eval <<FIELD>>=replace(<<FIELD>>,"4","R--")
| eval <<FIELD>>=replace(<<FIELD>>,"5","R-X")
| eval <<FIELD>>=replace(<<FIELD>>,"6","RW-")
| eval <<FIELD>>=replace(<<FIELD>>,"7","RWX")
)
So, for an example file permissions rights represented in octets as ‘077’, we can do this:

I find presenting *nix file attributes in such readable way to be very beneficial to the analyst (the less we need to guess about what we see on dashboards or in alerts/reports, the better).
The foreach command is a very handy SPL construct for many situations where we have to apply the very same business logic to multiple fields; that is, as long as their names can be addressed/referenced with a wildcard (in this case field names follow the incremental pattern: oct1, oct2, oct3 and can be represented as a wild card oct*).
Gotcha #2 – summary indexes
Everyone in the Splunk ecosystem knows and raves about tstatebut imho summary indexes are far more sexy! They allow us to cherry-pick a small subset of ‘interesting’ events from the gazillions of all incoming events, temporarily save them to a specific place (yes, summary index!), and often in some normalized/efficient/data enriched way (drop fields, do some patter recognition and normalization, add GeoIP data, etc.), so that querying this (far smaller!) snapshot of data is not only faster, but also more focused.
For example, a dedicated summary index (or indexes) could be used to store all observed invocations of say ‘rundll32.exe’, ‘mshta.exe’, ‘cscript.exe’, ‘wscript.exe’, ‘powershell.exe’, ‘pwsh.exe’ (on Windows systems), or perhaps all command line referencing ‘curl’ or ‘wget’ on Linux/Windows/macOS systems.
How cool is that?
You can literally drive a lot of commandline-based research this way. Leading to discovering new invocations, new tricks, or just using it to define per/endpoint base lines… it’s all there, in your summary index, easy to digest, easier to back-up, and fundamentally – a real threat hunting value amplifier.
Other uses of summary index can include building your own, custom implementation of a dynamic asset inventory (f.ex. any new host not present in the summary index and reporting ANY event can be added). And finally, while it is not humble to day, a few years ago my friend (much better Splunker than I am!) and I implemented a custom RBA (Risk Based Alerting) solution using Summary Indexes too! Data reduction and research opportunities that summary indexes offer cannot be understated…
Gotcha #3 – counting a number of character occurrences in a string
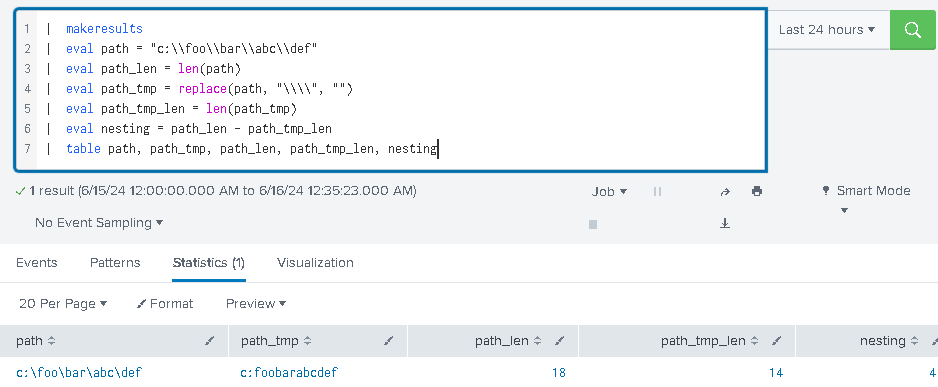
There is an interesting problem that we sometimes come across during threat hunting – how to count a number of occurrences of a specific character in a given string. And there are so many uses for this simple (yet difficult to implement) algorithm. For instance, one may ask – given a path, how deep is a nesting level of its folder structure? While we can answer it simply by counting how many forward/backward slashes we can count in a given path, the actual SPL implementation of this algo is not easily available, because there are no functions available yet that can facilitate it (AFAIK).
Here’s the gotcha: we can get a length of a string (path) and preserve it. We then replace all characters of interest (say: forward/backward slashes) with… nothing, and calculate this new string’s length. The difference between these two lengths is the value we are looking for!
Gotcha #4 – excluding long command line invocations
Analysis of command line invocations is HARD. We can pretend all we can, but in reality this is one of the hardest problems of process telemetry analysis. We obviously use exclusions, focus on specific programs, patterns, but if we still want to do a due diligence we actually need to end up clustering it all to make sure we ‘see it all’…
I find the length of logged commands to be an interesting property to play around with. If the process name is related to Java, Google Chrome, Microsoft Edge and other chrome-based browsers, or the invocations are coming from any type of macos/linux shell, you will see a lot of VERY long command lines… so, if the command line is that long, we can often simply exclude it from our main searches/summaries. BUT to avoid any misses, we can always add a compensating control that is specifically looking at these excluded, long command lines. And these may also be often normalized using various regular expression-based templates f.ex. focused on GUIDs, timestamp patterns, version numbers, etc. (see my old post for more details).
I believe that Divide and Conquer approach is fully justified.
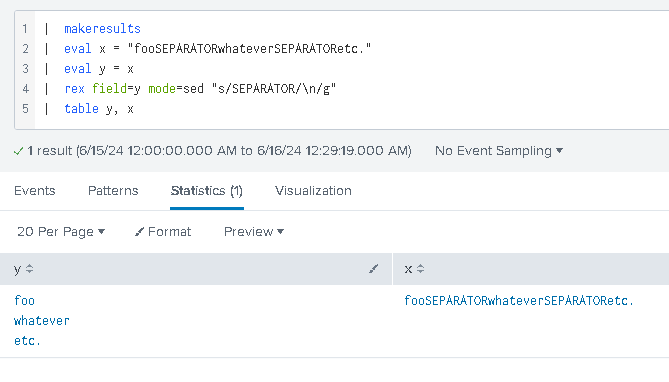
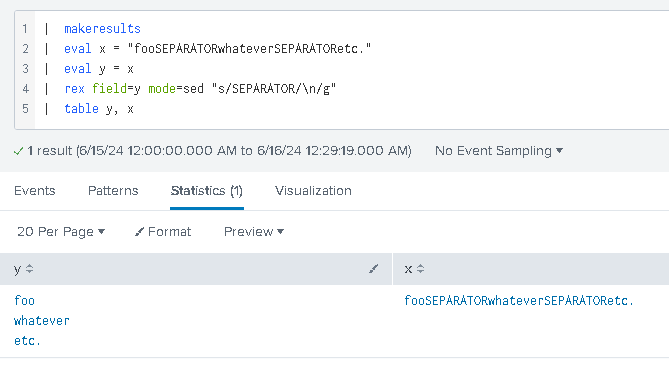
Gotcha #5 – adding line breaks
The SPL does not support new lines very well, so our output can often get messy… but… we can always use this construct:
| rex field=<filed_name> mode=sed "s/<something>/\n/g"
to add actual new lines to the output f.ex:
Gotcha #6 – URLs are… VERY complicated
The last gotcha is related to URLs. Anyone who did some SPL work for some time is familiar with the ut_parse_extended command that is a part of URL Toolbox.
The internet as we know is no longer English-centric. Support for Unicode-based domain names is omni-present and we can’t use basic regexes to parse URLs anymore. The URL Toolbox takes care of all these nuances offering URL parsing that supports non-English characters, less known TLD suffixes, and IDN.

GIPHY App Key not set. Please check settings