CVE-2019-1347: When a mouse over a file is enough to crash your system, Hacker News
1.9k Views
CVE – 2019 – 1347: When a mouse over a file is enough to crash your system
Analyze this yourself! Discover Timeless Analysis Live.
CVE – 2019 – 1347 is a vulnerability disclosed in october 2019 by Mateusz@ j 00 ruJurczyk in the Windows relocation mechanism when parsing a PE file. By simply placing your mouse cursor over the Proof of Concept file, a Blue Screen Of Death is triggered.
We thought theoriginal descriptioncould be positively completed with an analysis with REVEN, our timeless analysis tool. For this analysis we recorded several short traces to isolate and understand how specific bytes in the PE led to the crash.
In total, we will show that exactly four locations are responsible for the crash, and how this can help understand the bug itself.
The minimal bytes to be modified from the original file are the following:
Offset
Original
New
0xd0
00
3f
0x 120
00 C0
FF E7
0x 169
20
af
0x1ef
42
ff
Note: Throughout this post, we will call these locations “byte”, even though the second one involves two bytes.
A fistful of bytes: First and second location
To begin with, we recorded the crash triggered by thisPoCprovided in the (issue) . From theKeBugCheckcall we reach back the Page Fault and see that the address0xfffff 8035 b2ae7ffis not mapped, and won’t be.
A closer look at the memcpy arguments shows that this address is built as0xfffff (B2A) 00 0xe7ff, so we taint the value0xe7ffto find where it comes from.
We instantly find out that this value comes unchanged from the PoC PE. Indeed, modifying this value in the PE disables the crash. Opening the PoC in any PE editor confirms that the value is related to the Relocation Directory RVA, as stated also by theissue.
The forward taint has an advantage compared to the backward taint: flags are tainted too. This can be tedious in many cases but here it turns out to be very effective when applied to0xe7ff:
Firsts tests are just zero tests. The important one is the comparison with0xf 00 0. At first sight the alignment sounds like a simple overflow-related check, but it isn’t. We taint0xf 00 0, it actually comes from the PE:
The value0xe 03 fis the field SizeOfImage from the PE header (modified in the PoC). The value0xf 00 0is derived from this size as a 0x 1000 – aligned value. If we modify this entry to its original value, the crash doesn’t occur, proving that both of0xe7ff (and (0xe) fare directly linked to the crash.
We then tried to modify those two bytes in the original file, but unfortunately, it isn’t enough to trigger the BSOD. For the next parts we will determine the other needed bytes.
For a few bytes more
We decided to patch manually the file with the differences, in a -sort-of- dichotomic manner.
The idea is simple: using a PE editor, we compare the original file and the provided PoC. By applying / removing relevant modifications to the original file in correlation with the PoC, thetwo single bytestriggering the BSOD are isolated gradually. Note that we only had to perform this operation on the header part of the file, as the memory history reveals that the corpus of the file isn’t accessed.
This minimization could have been automated by a script that triggers and detect the BSOD in a VM, but in this case manual modification is enough.
Next part of this post analyzes how these two new bytes influence the CFG and eventually points out the bug. We recorded three traces more: the one induced by the minimal PoC (four locations modified), and two other traces where we let respectively the third byte and fourth byte unchanged. The two later tests don’t trigger the BSOD on purpose.
Third byte analysis
The third byte we modified is located at file offset0x 169, where we replaced0x 20by0xaf. A PE parser shows that it is related to a directory RVA, just like the relocation RVA mentioned earlier.
To detect where the CFG changed, we used the following naïve script with the Analysis Python API, that compares two traces instruction by instruction:
while(instructions_are_equal() TR1,tr2)):# Fetch next instruction from first trace and second tracetr1_id=1tr1=RVN1 .trace.transition() tr1_id)tr2_id=1tr2=RVN2 .trace.transition() tr2_id)
The full script is available in Appendix 1 .
The algorithm is effective enough as we will only focus on one function:MiRelocateImage. In a few seconds, we get this output:
python trace_diff.py --host1 localhost --port1 44389 --host2 localhost --port2 43633 --TR1 77868515 --TR2 65535121 INFO: Finding the difference between two traces ... INFO: Instructions are different at 77868565 - 65535171 INFO: Done
The results shows that the traces are divergent shortly after the beginning ofMiRelocateImage, and the function exits almost right after a flag is tested :
Now we analyze why this flag is set to0x1. We can follow it in memory in the trace that doesn’t crash:
This shows that the flag0x1comes from a check on a value,0xb, and that0xbcomes itself from the file, unchanged. But0xbisn’t the byte we modified, so we can ask, why is it linked to the flag?
The answer is that0xbis a value in a structure, and the modified value decides where this structure starts:
The value0x 2008– the 3rd byte that we modified to0xaf 08-, is responsible for pointing the beginning of a structure, and a value from this structure is checked to decide whether or not relocating the image at the beginning ofMiRelocateImage. When the byte0x 20is changed to0xaf, the offset pointing the start of the structure changes, the value in the structure is then different (with a high probability), the derived flag isn’t set, the execution ofMiRelocateImagecontinues, resulting eventually in the crash.
This third byte analysis doesn’t show the bug as itself, but nevertheless, it shows that REVEN can explain why it is important. Actually, instead of modifying the 3rd byte from0x 2008to (0xaf) , we can modify the aforementioned0xbvalue to0x0. This causes the system crash also, proving that our analysis is correct.
For the next part, we will analyze the crash itself, the bug, and how it is linked to the 4th byte.
crash, The bug, and The fourth byte
Taint forward against the fourth byte
Analyzing the fourth byte is indeed tricky.
First we can taint forward this byte from the moment it is parsed:
With IDA synchronized, we see that this byte is used as an index into the arrayMiImageProtectionArray, and the value fetched is0x6. Tainting this value0x6is also possible, yet in this case, the information given by the taint is verbose and difficult to analyze. We will continue this fourth byte analysis by having a look at the crash itself.
From the crash
From the beginning of this analysis, we only pointed out a page fault which couldn’t be resolved. But the page fault doesn’t seem to come from a common read overflow; the problem is elsewhere.
For this part we analyzed the code that precedes theKeBugCheckExcall:
We can see multiple checks on a zero value, leading to the crash. This value comes from memory at the end of an array containing what looks like PTE.
The question is, does the problem come from fetching the wrong PTE? (i.e. bad index in the PTE array?) or is it because there should be an entry there that doesn’t exist?
Next part answer this question.
Is offset in PTE array wrong?
First we can try to analyze where and how this PTE address is build. We can taint this address to see where it comes from:
The following code is responsible for the conversion:
At the beginning of this code, rdi contains the address0xfffff 8035 b2ae7ff, that needs to be mapped. This code doesn't seem to have any flaw, so we can deduce that probably, the problem is that the entry containing zero should have been populated, yet it isn't.
Entry in PTE array is not populated
It is very probable that this array is populated in a loop, so we can find out where other entries have been set and see why the empty one isn't:
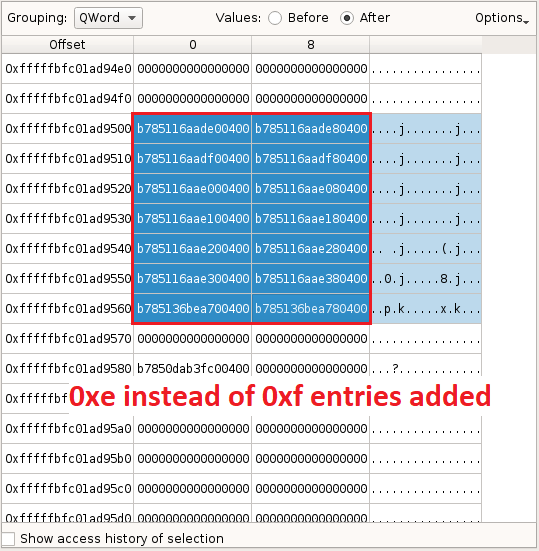
We reachMiAddMappedPtes. Basically, it takes as argument the amount of PTE to add, and adds them. Let's taint backward this number (ie0xf)), and almost immediately see that it comes from the first byte we've modified in the file:
The value0xfcorresponds to the required number of 0x 1000 - aligned blocks to handle a size of 0xe 03 f. This looks consistent, but the problem seems that even though0xfentries should be added,only 0xe effectively are:
Another thing we can do is executing the previous script to detect where the execution differs from a trace that doesn't crash:
python trace_diff.py --host1 localhost --port1 44389 --host2 localhost --port2 43633 --TR1 77868515 --TR2 65535121 INFO: Finding the difference between two traces ... INFO: Instructions are different at 77868565 - 65535171 INFO: Done
We analyze these results:
At some point, a branch is taken to callGetSharedProtosinstead ofMiGetSubsectionDriverProtos. This is probably interesting but right now we don’t know enough about the context to exploit this information.
We need to analyze the loop termination conditions, at the end of theMiAddMappedPtes, to understand why only0xeentries are added.
There are three consecutive checks:
0xfffff (a) EA 22cmpRBX,RSI0xfffff (a) EA 25jae0xfffff (a) EA 58() $
0x 33)0xfffff (a) EA 27cmpr 11,RDI0xfffff (a) **************************************************************************************************************************** (ea2a)JAE0xfffff (a) EA 78($( 0x4e)0xfffff (a) EA 78movrbp,qword(ptr)[rbp0x10]0xfffff (a) **************************************************************************************************************************** (ea7c)testRBP,RBP0xfffff (a) **************************************************************************************************************************** (ea7f)je0xfffff (a) D5B6($0x (EB))
First condition check – SizeOfImage
It is pretty straightforward: the upper bound correspond to0xfentries and it isn’t reached
The code just gets a pointer on the last entry of the array that will be filled.
Second condition check – Pointing out the chained list
The upper bound seems to be the number of 0x 1000 – aligned blocks needed for a section. Taint analysis shows that it is computed from the size of the section, located in the PE header.
More precisely, this number of page is set in a chained list entry, byMiParseImageSectionHeader:
This chained list entry is important as the last check depends on it.
Third condition check – Do we need to add one last PTE?
If the next entry in the chained list is empty (i.e. the current one is the last section), the algorithm checks whether or not it should add more pages. And this is where the bug occurs: instead of comparing the amount of page already effectively added with amount of page to be added, it compares the address in an array with the last entry of…a completely different array.
In the trace where the 4th byte isn’t tampered with (the crash is disabled), the code adds a new entry properly, but not in the trace that crashes. Here is what we can see in both:
Everything looks fine for the disabled test, but for the crash version, the first address compared is at a way higher address, hence the code considering that the upper boundary is reached and don ‘t need to add PTE anymore. The last entry isn’t populated, and the crash occurs when this last page is accessed, as no PTE exists for it.
Basically, what was intended:
// Check if another PTE is neededif(&array[current]&array[last]){add_entry();}
But in this case, arrays may differ, hence the comparison being faulty.
The 4th byte, the last piece of the puzzle, is demystified now.
4th byte: Forcing the bad comparison
(Impact)
Recall that the naïve trace differential showed thatGetSharedProtosis called instead ofMiGetSubsectionDriverProtos. The two arrays that are incorrectly compared, come from these functions, respectively. The bug could have stayed unnoticed but the fourth byte tampering forces the usage ofGetSharedProtosinstead ofMiGetSubsectionDriverProtos, leading to the faulty comparison.
Origin
The branch that callsGetSharedProtosis taken because of the value0x2in memory, we can use the memory history on this word:
Once again, we analyze the instructions right before this branch and see that the value inr8bis tested. This value is0x6, which for an attentive reader may ring a bell. Taint analysis may help to trace where it comes from, or in this case we just fetch where it has been modified a few instruction before.
Actually, the value0x6comes fromMiImageProtectionArray(a result found previously), and the index in this array was derived from the byte we modified in the file. This is how the 4th byte influences the CFG to force the comparison and trigger the bug.
Once upon a patch in the kernel
We recorded a last trace against an updated version of Microsoft Windows, to see how the bug is fixed.
Whilst we were expecting some checks around the faulty array comparison, the patch just avoids the need to reach that code.
InMiAddMappedPtes, we saw earlier that (0xfPTE are to be added. The code goes through a chained list containing structures that seem to represent each section, and the amount of PTE needed for each of these section. Let’s go through this chained list:
For each entry, we can see the pointer to the next entry at offset 0x 10, and the number of blocks to add at offset 0x2c. In the crash version, this is a recap of blocks needed:
section 1 needs 2 pages
section 2 needs 8 pages
section 3 needs 2 pages
section 4 needs 2 pages
0xf – 2 – 8 – 2 – 2=0x1last page to be added. Previously, the last page was added with an ad-hoc faulty piece of code that we described earlier.
In the patched version, we can see the following:
section 1 needs 2 pages
section 2 needs 8 pages
section 3 needs 2 pages
section 4 needs (3) pages
The last section has one more page, hence no need to add (through the faulty code) a last page. We can analyze the last round ofMiAddMappedPtesand see where this0x3comes from:
For each section,MiParseImageSectionHeaderscreates an entry , with (among other) the amount of 0x 1000 – block needed in it. This number is derived from the size defined in the PE header as we showed earlier.
Basically, the patch is: if there are still blocks to add compared to the SizeOfImage value (0xfblocks in total here), then when the last section is handled, the amount is replaced by the actual number of remaining needed pages.
The following pseudo code represents what is done in the patched version:
This ad-hoc check and add used to be inMiAddMappedPtes, they are moved now, so the faulty code isn’t executed anymore.
As such, the last PTE is correctly added and no crash occurs.
Conclusion
There is no previous analysis for this vulnerability at the time of writing. We showed how we could analyze it precisely with REVEN, minimized the PoC and explained the influence of each faulty byte. In particular, we used the taint feature many times to quickly go through many memory manipulation and find the origin of some values.
Even though the CFG is usually tedious to follow, thanks to the Python Analysis API and other features, we were able to point out where key branches were taken and analyze why. Moreover, we did analyze precisely how Microsoft patched this issue; and it is now easier to figure out if this patch is enough or not.
Finally, this logical error wasn’t trivial to analyze. The capability to navigate the trace in time instead of restarting again and again the parsing with a debugger allowed us to spare a fair amount of time.
Appendix 1
Naïve script to perform simple trace differential analysis. Given two traces and two transitions, this script returns the transition (“instruction number”) when the bytecode differs.
importArgparseimportreven2importlogginglogging.basicConfig (format='% (levelname)s: t% (message)s',level=logging.INFO)defparse_args():parser=argparse ****************ArgumentParser(description='Find the first different instruction between two traces n')parser.add_argument ('- host1',(metavar)='host1',dest='host1',help='Reven host 1, as a string''(default: "localhost")',default='localhost',type=str)parser.add_argument ('- port1',(metavar)='port1',dest='port1',help='Reven port for first server'', as an int (default: 13370) '',type=(int),default=13371)parser.add_argument ('- host2',(metavar)='host2',dest='host2',help='Reven host 1, as a string''(default: "localhost")',default='localhost',type=str)parser.add_argument ('- port2',(metavar)='port2',dest='port2',help='Reven port for second server'', as an int (default: 13370) '',type=(int),default=13372)parser.add_argument ('- tr1',(metavar)='tr1',dest='tr1',help='Start transition for the first trace',type=int)parser.add_argument ('- tr2',(metavar)='tr2',dest='tr2',help='Start transition for the second trace',type=int)args=Parser ****************parse_args()returnargsdefinstructions_are_equal() TR1,tr2):"" " From 2 transitions, return True if instructions are identicals. "" "returntr1.instruction.raw==TR2.instruction.rawif__ name __=='__ main __':args=parse_args()logging.info ("Finding difference between two traces ...")# Get a server instance for both tracesrvn1=reven2 RevenServer(args.host1,args.port1)rvn2=reven2 RevenServer(args.host2,args.port2)tr1_id=args TR1tr2_id=args .TR2tr1=RVN1 .trace.transition() tr1_id)tr2=RVN2 .trace.transition() tr2_id)i=0while(instructions_are_equal(TR1,tr2)):# Fetch next instruction from both tracesi=1tr1_id=1tr1=RVN1 .trace.transition() tr1_id)tr2_id=1tr2=RVN2 .trace.transition() tr2_id)ifi%100==(0):logging.debug ("{0} are identicals".format(i))logging.info ("Instructions are different at {0} - {1}".format(tr1.ID,TR2.(id))))logging.info("Done")
Analyze this yourself! Discover Timeless Analysis Live.





GIPHY App Key not set. Please check settings