

Gaming the system –
Forget chess and Go: The new AI frontier is multiplayer video games.

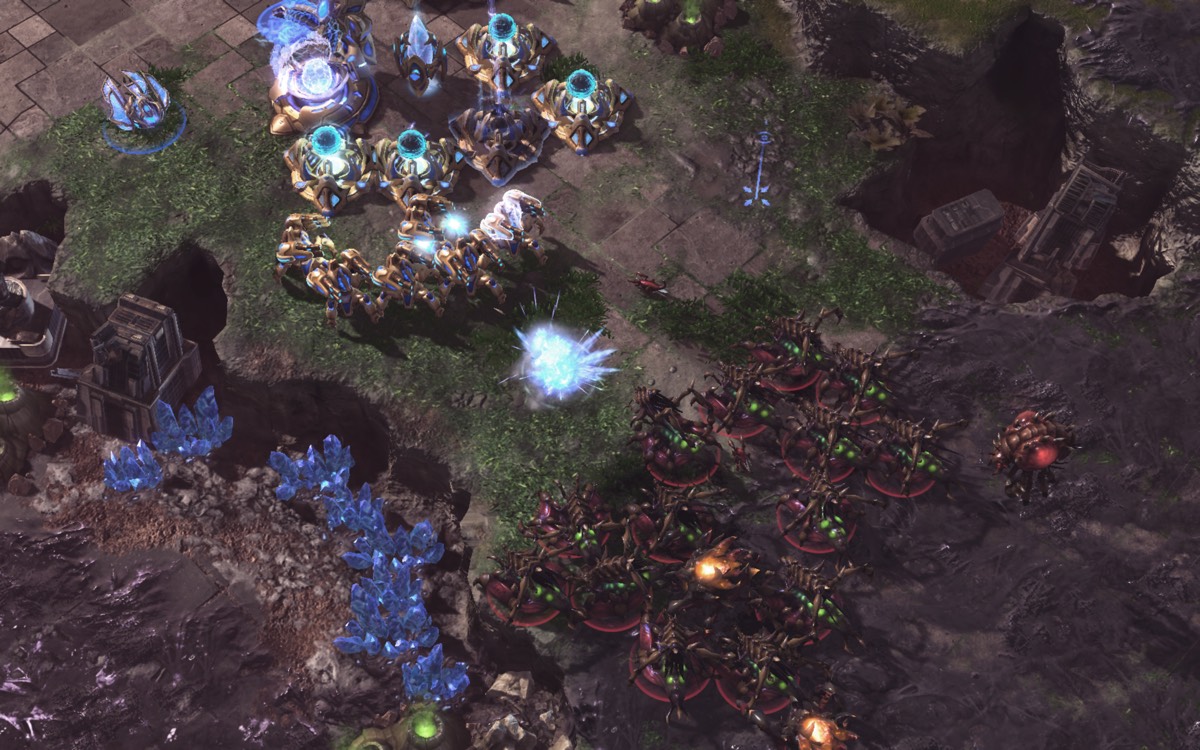
Enlarge/AlphaStar (Protoss , in green) dealing with flying units from the Zerg players with a combination of anti-air units (Phoenix and Archon).
DeepMind
Back in January, Google’s DeepMind teamannounced thatits AI, dubbed AlphaStar, had beaten two top human professional players atStarCraft. But aswe argued at the time, it wasn’t quite a fair fight. Now AlphaStar has improved on its performance sufficiently to achieve Grandmaster status inStarCraft II,using the same interface as a human player. The team described its work in a new paper in Nature.
“This is a dream come true,” said DeepMind co-author Oriol Vinyals, who was an avid StarCraft player 20 years ago. “AlphaStar achieved Grandmaster level solely with a neural network and general-purpose learning algorithms — which was unimaginable ten years ago when I was researchingStarCraft (AI using rules-based systems. “)
Late last year,we reported onthe latest achievements of AlphaZero, a direct descendent of DeepMind’s AlphaGo, which made headlines worldwide in 2016 by defeating Lee Sedol, the reigning (human) world champion in Go. AlphaGo gota major upgradelast year, becoming capable of teaching itself winning strategies with no need for human intervention. By playing itself over and over again, AlphaZero trained itself to play Go from scratch in just three days and soundly defeated the original AlphaGo 100 games to 0. The only input it received was the basic rules of the game. Then AlphaZerotaught itselfto play three different board games (chess, Go, and shogi, a Japanese form of chess) in just three days, with no human intervention.
The secret ingredient: “reinforcement learning, “in which playing itself for millions of games allows the program to learn from experience. This works because AlphaZero is rewarded for the most useful actions (i.e., devising winning strategies). The AI does this by considering the most probable next moves and calculating the probability of winning for each of them. The most recent version combined deep reinforcement learning (many layers of neural networks) with a general-purpose Monte Carlo tree search method. As chess grandmasterGary Kasparov wrotein an editorial in Science last year, “Instead of processing human instructions and knowledge at tremendous speed, as all previous chess machines, AlphaZero generates its own knowledge.”
Enlarge/AlphaStar (Zerg, in red) defending an early aggression where the opponent built part of the base near AlphaStar’s base, showcasing robustness.
DeepMind
With AlphaZero’s success, DeepMind’s focus shifted to a new AI frontier: games of partial (incomplete) information, like poker, and multi-player video games likeStarcraft II.StarCraft IIis also a game of incomplete information, and there is no single best strategy, much like playing rock-paper-scissors. It requires long-range planning ability and real-time decision-making in a large action space. Not only is the gameplay map hidden to players, but they must also control hundreds of units (mobile game pieces that can be built to influence the game) and buildings (used to create units or technologies that strengthen those units) simultaneously. As Ars’ Tim Lee (an avidStarCraftplayer)wrote in January:
“StarCraftrequires players to gather resources, build dozens of military units, and use them to try to destroy theirStarCraftis particularly challenging for an AI because players must carry out long-term plans over several minutes of gameplay, tweaking them on the fly in the face of enemy counterattacks. says that prior to its own effort, no one had come close to designing aStarCraftAI as good as the best human players. “
That earlier version of AlphaStar also relied on deep reinforcement learning to teach the program to mimic human strategies. At that point, the AI was proficient enough to defeat Elite-level players roughly 95% of the time . Then the DeepMind team created variants of that AI, each adopting a different playing style, and placed them into a virtualStarCraftleague. This allowed the agents to learn from their mistakes and evolve their strategies accordingly. Then DeepMind selected the five strongest agents and pitted them against two human professional players: Dario “TLO” Wunsch and Grzegorz “MaNa” Komincz. The AI defeated its human challengers in all ten games.
That said, it wasn’t quite a fair fight. “The ultimate way to level the playing field would be to make AlphaStar use the exact same user interface as human players,”Lee wrotein January. “The interface could be virtualized, of course, but the game should get the same raw pixel inputs as a human player and should be required to input instructions using a sequence of mouse movements and keystrokes — with inputs limited to speeds that human hands can achieve . This is the only way to be completely sure that AlphaStar isn’t giving its software an unfair advantage. “
Playing like a human
This latest version of AlphaStar goes a long way toward addressing those issues, combining deep reinforcement learning with multi-agent learning and imitation learning directly from game data, honed once again via a virtual league. Per a blog post by Vinyals and fellow DeepMind co-author Wojciech Czarnecki, the new, improved AlphaStar was subject to the same constraints under which humans play, and it played on Battle.net “using the same maps and conditions as human players.”

Enlarge/AlphaStar (Zerg, in green) winning a final encounter using late-game, high-tech units.
DeepMind
“The key insight of the league is that playing to win is insufficient,” Vinyals and Czarnecki wrote of the improvements to this latest incarnation of AlphaStar. “Instead, we need both main agents whose goal is to win versus everyone, and also exploiter agents that ‘take one for the team.’ focusing on helping the main agent grow stronger by exposing its flaws, rather than maximizing their own win rate. Using this training method, the current league learns all its complexStarCraft IIstrategy in an end-to-end fashion — as opposed to the earlier incarnation of our work, which stitched together agents produced by a variety of methods and algorithms. “
The AI can also now play as or against the three races in (Starcraft II) : Protoss, Terran, and Zerg. (The earlier version only played Protoss vs. Protoss.) DeepMind pitted AlphaStar against human players in a series of online games. The AI was rated at Grandmaster level for all threeStarCraft IIraces and above 99 .8% of officially ranked human players. It’s the first AI to achieve that status in a popular professional e-sport, without using a simplified version of the game. That’s a strong indication that these types of general-purpose machine-learning algorithms could be used to solve complex real-world problems such as personal assistants, self-driving cars, or robotics — all of which require real-time decisions on the basis of imperfect information.
“At DeepMind, we’re interested in understanding the potential — and limitations — of open-ended learning, which enables us to develop robust and flexible agents that can cope with complex real-world domains, “Vinyals and Czarnecki wrote. “Games likeStarCraftare an excellent training ground to advance these approaches, as players must use limited information to make dynamic and difficult decisions that have ramifications on multiple levels and timescales. “
And this time around, it appears to have been a fair fight. “I’ve found AlphaStar’s gameplay impressive,” Wunsch said of this most recent incarnation. “The system is very skilled at assessing its strategic position, and knows exactly when to engage or disengage with its opponent. And while AlphaStar has excellent and precise control, it doesn’t feel superhuman — certainly not on a level that a human couldn ‘ Overall, it feels very fair — like playing a ‘real’ game ofStarCraft. “
DOI:Nature, 2019.. 1038 / s 41586 – 019 – 1724 – z(About DOIs).

(Read More


{kind=link}
GIPHY App Key not set. Please check settings