
We are pleased to provide binaries for file_textarray_fdw and odbc_fdw for PostgreSQL (Windows) – bit.
To use these, copy the files into your PostgreSQL (Windows) – bit install folders in same named folders and then run CREATE EXTENSION as usual in the databases of your choice. More details in the packaged README.txt
Continue reading “PostgreSQL 11 64 – bit Windows FDWs “
Ok, let’s face it, I like SQL. A lot. I think it’s a fine DSL given how powerful it is, and I respect its initial goal to attract non developers and try to build English sentences rather than code. Also, I understand that manually hydrating your collection of objects in your backend developement language is not the best use of your time. And that building SQL as strings makes your code ugly.
In our previous articles we had a look at What is an SQL relation? and What is a SQL JOIN ?. Today, I want to show you what is an aggregate in SQL. You might have heard about Map / Reduce when Google made it famous, or maybe some years before, or maybe some years later. The general processing functions map and reduce where invented a very long time ago. The novelty from the advertising giant was in using them in a heavily distributed programming context.
It took me quite some time before I could reason efficiently about SQL JOINs. And I must admit, the set theory diagrams never helped me really understand JOINs in SQL. So today, I want to help you understand JOINs in a different way, hoping to make the concept click at once for you too! As we saw in the previous article What is an SQL relation ?, in SQL a relation is a collection of objects, all sharing the same definition.
If you’re like me, understanding SQL is taking you a long time. And some efforts. It took me years to get a good mental model of how SQL queries are implemented, and then up from the lower levels, to build a mental model of how to reason in SQL. Nowadays, in most case, I can think in terms of SQL and write queries that will give me the result set I need.
Soon it’s that time of the year again – basically a 2nd Christmas for followers of the “blue elephant cult” if you will :). I’m, of course, referring to the upcoming release of the next PostgreSQL major version, v 12. So I thought it’s about time to go over some basics on upgrading to newer major versions! Database upgrades (not only Postgres) are quite a rare event for most people (at least for those running only a couple of DB-s). Since upgrades are so rare, it’s quite easy to forget how easy upgrading actually is. Yes, it is easy – so easy that I can barely wrap my head around why a lot of people still run some very old versions. Hopefully, this piece will help to convince you to upgrade faster in the future :). For the TLDR; (in table version) please scroll to the bottom of the article.
Why should I upgrade in the first place?
Some main points that come to my mind:
- More security
Needless to say, I think security is massively important nowadays! Due to various government regulations and the threat of being sued over data leaks, mistakes often carry a hefty price tag. Both new and modern authentication methods and SSL / TLS version support are regularly added to new PostgreSQL versions. - More performance without changing anything on the application level!
Based on my gut feeling and on some previoustesting, typically in total around ~ 5 – 15 % of runtime improvements can be observed following an upgrade (if not IO-bound). So not too much… but on some releases (9.6 parallel query, 10 .0 JIT for example) a possibly game changing 30 – 40% could be observed. As a rule, the upgrades only resulted in upsides – over the last 8 years, I’ve only seen a single case where the new optimizer chose a different plan so that things got slower for a particular query, and it needed to be re- written. - New features for developers
- Every year, new SQL standard implementations, non-standard feature additions, functions and constructs for developers are introduced, in order to reduce the amounts of code writt
[…]
Any long-time user of Postgres is likely familiar with VACUUM, the process that ensures old data tuples are identified and reused to prevent unchecked database bloat. This critical element of maintenance has slowly, but surely, undergone incremental enhancements with each subsequent release. Postgres 12 is no different in this regard. In fact, there are two […]
The world’s most valuable resource is no longer the oil or gold, but data. And at the heart of data lies the database which is expected to store, process and retrieve the desired data as quickly as possible. But having a single database server doesn’t mostly serve the purpose. A single server has its drawbacks with a huge risk of data loss and downtime.
So most data platforms use multiple replicated database servers to ensure high availability and fault tolerance of their databases. In such an environment, how can we maximize performance against the resourced being used?
One of the questions I get asked very often from Pgpool-II users is, what is the performance benefit of using load balancing of Pgpool-II? Once in a while, we get complains from users that they get better performance when they connect directly to PostgreSQL than through Pgpool-II, even when the load balancing is working fine. How true is this complain?
In this blog, I’ll benchmark the performance of the Pgpool-II load balancing feature against a direct connection to PostgreSQL.
Before we start measuring the actual performance, let’s start with what is Pgpool-II load balancer and why we should use it.
Replicated PostgreSQL servers.
Almost in every data setup, we need more than one copy of database servers to ensure minimum or zero downtime and to safeguard against data loss. For that, we use the replicated database servers.
There are many ways to create a replicated PostgreSQL cluster, which is the topic for some other blog post, but most of the replication solution exists for PostgreSQL supports one-way replication. That means one master PostgreSQL server feeding data to one or multiple standby servers. and in this setup, only maser server is capable of handling the write queries while standby servers sit idle waiting for the moment when the master goes down and one of them gets promoted to become a new master.
This setup is good enough to handle server failures and to provide the high availability but it is not
[…]

ThePostreSQL Operatorprovides users with a few different methods to perform PostgreSQL cluster operations, via:
- a REST API
- pgo, PostgreSQL Operator Command Line Interface (CLI)
- Directly interfacing with Kubernetes, including various APIs and custom resource definitions (CRDs).
While the REST API and pgo provide many conveniences, there are use cases that require the third method, i.e. interacting directly with Kubernetes to create the desired PostgreSQL cluster setup.
To demonstrate this, let’s look at how we can manipulate the CRD responsible for managing PostgreSQL clusters to create a new cluster managed by the PostgreSQL Operator.
![]()
PostgreSQL connection stringsembedded in your application can take two different forms: the key-value notation or thepostgresql: //URI scheme. When it comes to usingpsqlthough, another form of connection string is introduced, with command line options- h -p -Uand environment variable support.
In this short article you will learn that you can use either of the three different forms inpsqland thus easily copy & paste you application connection string right at the console to test it!
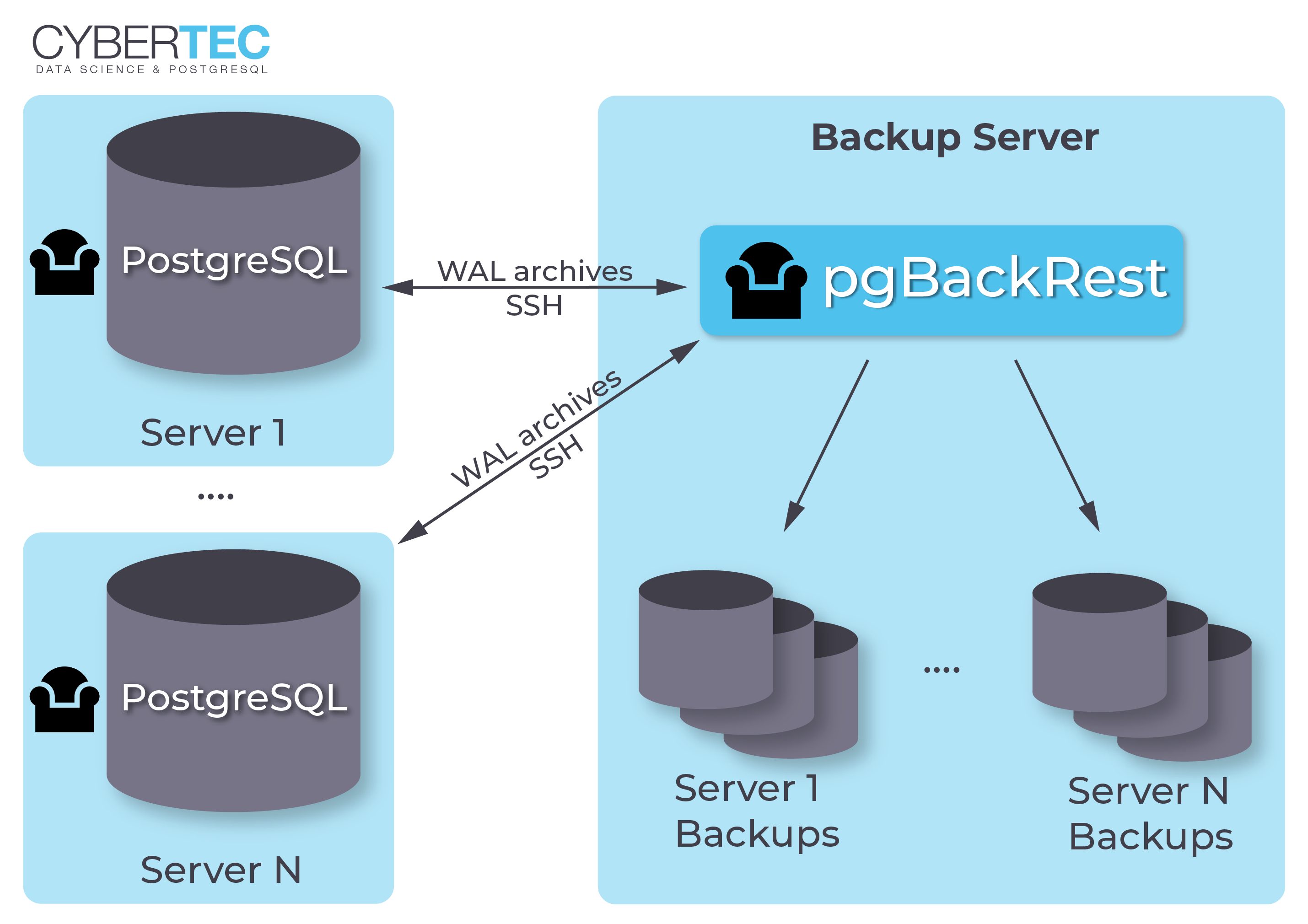
Inmy previous post about pgBackRest, we saw how to install and setup pgBackRest and make a backup of a PostgreSQL database with it. It was a very basic single server setup, only intended to get the hang of the tool. Such setups are not used in a production environment, as it is not recommended (or rather does not serve the purpose) to perform the backup on the same server where the database is running.
So: let’s get familiar with how remote backup servers are set up with pgBackRest, and how a full and incremental backup is performed from the backup server and restored on the database server.
We need two servers. Let’s call ours:
-
pgbackup -
DB1
Installing pgbackrest:
We need to install pgBackRest on the database and the backup server. Make sure you install the same version on both.
For the database server, please follow the installation steps frommy previous post. The steps are slightly different for the backup server, since it is a better practice to create a separate user to own the pgBackRest repository.
Create apgbackrestuser on the backup server
sudo adduser --disabled-password --gecos "" pgbackrest
Install required Perl package and pgBackRest from a package or manually on pgbackup as below
sudo apt-get install libdbd-pg-perl sudo scp BUILD_HOST: / root / pgbackrest-release-2. 14 / src / pgbackrest / usr / bin / sudo chmod 755 / usr / bin / pgbackrest
Create pgBackRest configuration files, directories and repository onpgbackup
sudo mkdir -p -m 770 / var / log / pgbackrest sudo chown pgbackrest: pgbackrest / var / log / pgbackrest sudo mkdir -p / etc / pgbackrest sudo mkdir -p /etc/pgbackrest/conf.d sudo touch /etc/pgbackrest/pgbackrest.conf sudo chmod 640 /etc/pgbackrest/pgbackrest.conf sudo chown pgbackrest: pgbackrest /etc/pgbackrest/pgbackrest.conf sudo mkdir -p / var / lib / pgbackrest sudo chmod 750 / var / lib / pgbackrest sudo chown pgbackrest: pgbackrest / var / lib / pgbackrest
Now we are ready to proceed with enabling c
[…]
Master branch ofPSPGsupports sort by column selected by vertical cursor.
Why I wrote this feature? You can try to list of tables inpsqlby DT command. The result is sorted by schema and by name. Sometimes can be interesting to see result ordered by table’s sizes. Now it is easy. PressAlt-vto show vertical cursor. Later move to right to “Size” column. Then pressdas descendent sort. You can get resuly like attached screenshot:

The sort is working only on numeric columns (but units used byPSQLare supported)

PostgreSQL12, the latest version of the “world’s most advanced open source relational database,” is being released in the next few weeks, barring any setbacks. This follows the project’s cadence of providing a raft of new database features once a year, which is quite frankly, amazing and one of the reasons why I wanted to be involved in the PostgreSQL community.
In my opinion, and this is a departure from previous years, PostgreSQL 12 does not contain one or two single features that everyone can point to and say that “this is the ‘FEATURE’ release,” (partitioning and query parallelism are recent examples that spring to mind). I’ve half-joked that the theme of this release should be “PostgreSQL 12: Now More Stable “- which of course is not a bad thing when you are managing mission critical data for your business.
And yet, I believe this release is a lot more than that: many of the features and enhancements in PostgreSQL 12 will just make your applications run betterwithout doing any work other than upgrading!
(… and maybe rebuild your indexes, which, thanks to this release, is not as painful as it used to be)!
It can be quite nice to upgrade PostgreSQL and see noticeable improvements without having to do anything other than the upgrade itself. A few years back when I was analyzing an upgrade of PostgreSQL 9.4 to PostgreSQL 10, I measured that my underlying application was performing much more quickly: it took advantage of the query parallelism improvements introduced in PostgreSQL 10. Getting these improvements took almost no effort on my part (in this case, I set themax_parallel_workersconfig parameter).
Having applications work better by simply upgrading is a delightful experience for users, and it’s important that we keep our existing users happy as more and more people adopt PostgreSQL.
So, how can PostgreSQL 12 make your applications better just by upgrading? Read on!
![]()
The PostgreSQL Conference Europe team will allow all PostgreSQL related Open Source projects to place flyers or stickers on the PGEU table during the conference.
The following conditions apply:
- The material must be about a PostgreSQL related project
- No company sponsoring or endorsement is allowed on the material (this includes the backside, small print, and also includes any advertisement for the printing company )
We reserve the right to remove or return any material which we deem not suitable for the conference. Please talk to our staff before placing material on the table.
We expect around 550 visitors this year, but people might grab more material or stickers for friends or colleagues.
In order to prepare for the start of training season (you can see our “stock” training offeringshereby the way ), I’ve updated our small “Postgres features showcase”project, and thought I’d echo it out too. Main changes – coverage on some features of the current v 11 release and also from the upcoming v 12.
Short project background
The project was introduced some two yearsago– the main idea of theprojectitself is to provide a compact and “hands-on” set of commented samples to help newcomers get up to speed with Postgres. Of course, one cannot beat official documentation but sadly, the documentation for Postgres doesn’t have a dedicated folder for working code samples. However, thetutorialcan be helpful. So, the idea is to provide some commented SQL for the “code-minded” people to quickly see and “feel” the concepts to get the gist of it faster.
Updated list of topics covered
- Connecting
- Creating databases / roles
- Transaction management
- Creating / altering tables
- Partitioning and other table modifiers
- Most common data types
- Constraints
- Views / materialized views
- Stored functions / procedures
- Triggers
- Enums / custom types
- Extensions
- Row-level security
- Analytical and parallel queries
- Indexing
- String processing and arrays
RFC
If you see that this project is somewhat useful but could be improved even more, we would be very glad if you take the time to provide your ideas asGithub issues– or even better – directly asPull Requests. Thanks!
The postUpdates for the Postgres Showcase projectappeared first onCybertec.
I released new version ofPSPG. Now, colum searching and vertical cursor is supported.
Nine months ago, I started development of a key management extension forpgcrypto.The tool is calledpgcryptokeyand is now ready for beta testing.
It uses two-levels of encryption, with an access password required to use the cryptographic keys. It supports setting and changing the access password, multiple cryptographic keys, key rotation, data reencryption, and key destruction. It also passes the access password from client to server without it appearing in clear text in SQL queries, and supports boot-time setting. The extension leverages pgcrypto and Postgrescustom server variables.
PLpgSQL is simple (but relatively power) specialized language. It is specialized for usage inside PostgreSQL as glue of SQL statements. It is great language for this purpose (and can be bad if it is used differently – for high cycles numeric calculation for example).
Originally a implementation of PLpgSQL language was really simple – it was very simple language with possibility to execute embedded SQL. But there was not possibility to check syntax of this SQL in validation time.
Note: PLpgSQL is a interpret of AST (abstract syntax tree) nodes. There is a valid ation stage (when code is parsed into AST), and evaluation stage (runtime), when AST (parsed again when code is first executed) is interpreted.
Old SPI (Stored Procedure Interface) had not any API for validation of SQL without execution. Almost all checks in this time was at runtime. It was not too practical – so some checks (check of SQL syntax) are at validation stage now. Still PLpgSQL validator doesn’t check a validity of SQL identifiers (tables, columns, functions, … names). Now, there are two reason why the validator doesn’t do it: a) we have not any other tools how to solve cyclic dependencies, b) Postgres’s local temp tables – PostgreSQL temporary tables are created at runtime and doesn’t exists at validation time – so PLpgSQL validator should not to check validity of SQL identifiers – they should not to exists in this time.
CREATE TABLE bigtable (id int, v int);
INSERT INTO bigtable
(SELECT random () ***********************************************************************************************************************************), random () * 10000
FROM generate_series (1, 1000000);
CREATE INDEX ON bigtable (id);
VACUUM ANALYZE bigtable;CREATE OR REPLACE FUNCTION example 01 (_ id numeric)
RETURNS numeric AS $$
DECLARE
r record;
s numeric DEFAULT 0;
BEGIN
FOR r IN SELECT * FROM bigtable WHERE id=_id
LOOP
s:=s rk;
END LOOP;
END;
$$ LANGUAGE plpgsql;
This code has lot of issues, but no one is a problem for buildin plpg […]
Here we go through the motions af adding binary input / output functions to an already existing type. We start by introducing a program that tests binary I / O for the given types, then show how to implement the binary I / O in C and finally how to fix the PostgreSQL catalog tables for the new functionality. We also include the changes in the installation script for normal installation of the new version.
Table of Contents
Adding the Binary I / O Functions
Fixing the Hashtypes Extension
Testing Binary I / O
Here we present a program that performs binary input / output with the various SHA data types in thehashtypesextension. See thedownload sectionlater .
The Readme
Test the various binary I / O routines of the SHA data types.
Prerequisites: the hashtypes extension has been created on a given database, like so
create extension hashtypes;
with version 0.1.6 or later.
This program performs a simple binary I / O test of the various SHA types, from SHA1 to SHA 512.
The usage is very simple,
shabin "connection string"
example,
shabin "host=localhost port=5432 dbname=foo user=bar "
and it will connect to the database with the given string, and attempt to make query of the form
select digest1, digest 224, digest 256, digest 384, Digest 512;
where each of the digests are of the same SHA type. It does this by querying the SHA type oids first, and then uses them to feed each digest to the PostgreSQL server.
If there is an error, the program will print a message to standard error and returns one to the operating system. On a successful run, the program prints a success message and returns zero to the operating system.
The Shabin Program
Test the various binary I / O routines of the SHA data types.
PostgreSQL header.
#include
System dependent networking headers, for ntohl ().
#ifdef _WIN 32 #include#else #include #endif
Sta
[…]
A few of days ago a new release of PgBouncer has been released, with the addition of SCRAM support!
Three days agoPgBouncer 1. 11has been released, and one feature that immediately caught my attention was the addition of / SCRAM support for password /.
SCRAMis currently the most secure way to use password for PostgreSQL authentication and has been around since version ~ 10 ~ (so nearly two years).SCRAMsupport for PgBouncer has been a / wanted feature / for a while, since not having it prevented users of this great tool to useSCRAMon the clusters.
Luckily, now this has been implemented and [the configuration of the PgBouncer account] (https://pgbouncer.github.io/config.html#authentication-file-format** is similar to the plain and ~ md5 ~, so it is very simple .
I really love PgBouncer and, with this addition, I can now upgrade my servers to / SCRAM /!Thank you PgBouncer developers!
How many working hours are there in a range of dates?
A few days ago there was a verynice thread in Thepgsql-generalmailing listasking for ideas about how to compute working hours in a month.
The idea is quite simple: you must extract the number of working days (let’s say excluding sundays) and multiple each of them for the number ofhours per dayand then get the sum.
There are a lot of nice and almostone-linersolutions in the thread, so I strongly encourage you to read it all!
I came up with my own solution, that is based onfunctions, and here I’m going to explain it hoping it can be useful (at least as a starting point).
You can find the code, as usual, on myGitHub repository related to PostgreSQL.
The workhorse function
One reason I decided to implement the alghoritm using a function was because I want it to be configurable. There are people, like me, that do a job where the working hours are different on a day-by-day basis. So, assuming the more general problem of computing the working hours between two dates, here there’s a possible implementation:
(CREATE)OR(REPLACE)FUNCTIONcompute_working_hours(begin_day(DATE),(end_day) (DATE),_ saturdayBoolean(DEFAULT) (false),_ hour_templateReal[](DEFAULT)ARRAY[8,8,8,8,8,8,8] ::(real)[],_ exclude_days(date)[]DEFAULT(NULL))...
pgBackRest is an open source backup tool for PostgreSQL which offers easy configuration and reliable backups. So if you want to protect your database and create backups easily, pgBackRest is a good solution to make that happen. In this blog, we are going to go through the basic steps of using pgBackRest for full and differential backup of PostgreSQL.
Some of the key features of pgBackRest are:
- Parallel backup & restore
- Local and remote operations
- Full, incremental & differential backups
- Backup rotation & archive expiration
- Backup integrity
- Page checksums
- Resume backups
- Streaming compression and checksums
To read about them more in detail, please visitpgbackrest.org.
Here, we are going to build pgBackRest from the source and install it on the host where a test DB cluster is running.
Installation:
Installing from Debian / Ubuntu packages:
sudo apt-get install pgbackrest
For manual installation, download the source on a build host.Please avoid building the source on a production server, as the tools required should not be installed on a production machine:
Download pgBackRest Version 2. 14:
sudo wget -q -O - https://github.com/pgbackrest/pgbackrest/archive/release/2.14 .tar.gz | sudo tar zx -C / root
Install the dependencies and check for 64 – bit integers:
sudo apt-get install build-essential libssl-dev libxml2-dev libperl-dev zlib1g-dev perl -V | grep USE _ 64 _ BIT_INT
Build pgbackrest package:
(cd /root/pgbackrest-release-2.14 / src && ./configure) make -s -C /root/pgbackrest-release-2.14 / src
Copy from build host to DB host:
sudo scp BUILD_HOST: / root / pgbackrest-release-2. 14 / src / pgbackrest / usr / bin / sudo chmod 755 / usr / bin / pgbackrest
Install Perl packages:
sudo apt-get install libdbd-pg-perl
pgBackRest config files & directories on DB test host:
sudo mkdir -p -m 770 / var / log / pgbackrest sudo chown postgres: postgres / var / log / pgbackrest sudo mkdir -p / etc / pgb
[…]
One of the amazing things about the PostgreSQL community is launching releases like clockwork. On 8/8 / 2019 the PostgreSQL community not only launched the minor versions for PostgreSQL 11 and old major versions but also a new Beta 3 version for upcoming PostgreSQL 12.
On AWS, you can check versions of PostgreSQL available in your region as follows:
$ aws rds describe-db-engine-versions --engine postgres --query 'DBEngineVersions [*]. EngineVersion '
[
"9.3.12",
...
"11.2",
"11.4"
]
You will not see any beta versions out there. Pre-release versions for PostgreSQL in AWS are available in the Preview Environment within US East 2 (Ohio). If you are using the cli you have to add the region us-east-2 and also the url endpoint rds-preview.us-east-2.amazonaws.com to your CLI commands.
$ AWS RDS describe-db-engine-versions --engine postgres
--query 'DBEngineVersions [*]. EngineVersion'
--region us-east-2 --endpoint https: //rds-preview.us-east-2.amazonaws. com
[
"12.20190617",
"12.20190806"
]
The versions displayed are bit cryptic but they denote the major version followed by date when the build was synced for the preview release. The version description will be more friendly to read than the version itself.
$ aws rds describe-db-engine-versions --engine postgres
--query 'DBEngineVersions [*] .DBEngineVersionDescription '
--region us-east-2 --endpoint https://rds-preview.us-east-2.amazonaws.com
[
"PostgreSQL 12.20190617 (BETA2)",
"PostgreSQL 12.20190806 (BETA3)"
]
Lets deploy an instance of PostgreSQL Beta 3 aka version 12. 20190806.
$ aws rds create-db-instance
- engine postgres --engine-version 12. --db-instance-identifier mypg 12 B3
- allocated-storage 100 --db-instance-class db.t2.small
- db-name benchdb --master-username pgadmin --master-user-password SuperSecret
- region us-east-2 --endpoint https: //rds-preview.us-east-2.amazonaws
[…]
We have now posted ourschedule. There are a few session still remaining particularly on the sponsor tracks, but almost all other sessions have been scheduled. Of course, individual sessions are still subject to change in case of unforeseen circumstances.
(Registration) is still open, but selling fast so we recommend you secure your seats! One of ourtrainingsessions is sold out at this point, but the others have a few seats left.

While PostGIS includes lots of algorithms and functionality we have built ourselves, it also adds geospatial smarts to PostgreSQL by linking in specialized libraries to handle particular problems:
![]()
I spent some more time on the PL / Proxy code base in order to make it compiling against upcoming PostgreSQL 12.
In myyesterday blog postI reported some stupid thougth about compiling PL / Proxy against PostgreSQL 12.
I was too stupid to hit the removal ofHeapTupleGetOid(as ofcommit (B) E8F (fa) ************************************************************************************************************************************************** (e) ****************************************************************************************************************************************************************************************** (F0) c4b6bb 3776106), and after having read the commit comment with more accuracy, I found how to fix the code (at least I hope so!)
Essentially, wherever I found usage ofHeapTupleGetOidI placed a preprocessor macro to extract theForm_pg _structure and use the normal columnOIDinstead , something like:
# if PG_VERSION_NUM (Oid)namespaceId=HeapTupleGetOid(tup);# elseForm_pg_namespaceform=(Form_pg_namespace)(GETSTRUCT)((tup)); OidnamespaceId=(form)->(OID);# endif
I strongly advise to not use this in production, at least until someone of the PL / Proxy authors have a look at the code! However the tests pass on PostgreSQL 12 beta2 on Linux .
You can find thepull requestthat also includes my previous pull request to make PL / Proxy work against PostgreSQL 11 and FreeBSD.
I hope it can help pushing a new release of this tool.
PL / Proxy is a procedural language implementation that makes really easy to do database proxying, and sharding as a consequence. Unluckily getting it to run on PostgreSQL 11 and FreeBSD 12 is not for free.
PL / Proxyis a project that allows database proxying, that is a way to connect to remote databases, and as a consequence allows for / sharding / implementations.
The idea behind PL / Proxy is as simple as elegant: define a minimalistic language to access remote (database) objects and, more in particular, execute queries.
Unluckily, the latest stable release of PL / Proxy is2.8and is dated (October 2017, that meansPostgreSQL 10! There are a couple of Pull Requests to make it working against PostgreSQL 11, but hey have not been merged and the project code seems in pause.
Today I created acumulative pull requestthat does a little adjustments to allow the compilation on FreeBSD 12 against PostgreSQL 11
My pull request is inspired and borrows changes from other two pull requests:
- pr – 31and credits toLaurenz Albe;
- pr – 33that has been merged into mine, and credits toChristoph Berg.
Then I added a compiler flag to adjust headers on FreeBSD 12, as well as dropped an old Bison syntax since this should be safe enough on modern PostgreSQL (at least 9.6 and higher.Some bit here and there to make all tests to pass against PostgreSQL 11, and everything seems right now.
** It is important to warn thatmy versionis notproduction readybecause it should be reviewed by at least one PL / Proxy developer.
And what about PostgreSQL 12?
Well, …
Today I released new version ofPSPG. There is only one change – vertical cursor support (press Alt-v). This feature can help orientation in some larger tables now. I would to use vertical cursor for resorting rows (by cursor column) support in next version.


On Windows and as of 11 5,PostgreSQL has a bug when trying tocopyfrom a huge file. According to stack overflow, this does not appear on earlier releases like PostgreSQL 10.
For example, given a table
create table pwned (passwd sha1 not null, count int4 not null);
and when trying to copy from thepwned password listwhich is about 24 GB uncompressed,
copy pwned (passwd, count) from 'c: src postgres pwned pwned-passwords-sha1-ordered-by-hash-v5.txt' with (format text, delimiter ':');
fails and the message follows.
ERROR: could not stat file "c: src postgres pwned pwned-passwords-sha1-ordered-by-hash-v5.txt": Unknown error
To work around this, we can pipe the file through a command;
copy pwned (passwd, count) from program 'cmd / c "type c: src postgres pwned pwned-passwords-sha1-ordered-by-hash-v5.txt"' with (format text, delimiter ':' );
which results in
COPY 555278657
and we can happily create an index and query the table.
The trick here is that we runcmdin sigle command mode with the/ Cflag, and tell it totypeout the file we want tocopy from.
Bug Report
Unfortunately, I am unsure how to report a bug related exclusively to Windows builds, so I have not tried to report the bug through appropriate channels.
Contact
The author can be reached at [email protected].
Row Level Security (RLS) is one of the key features in PostgreSQL. It can be used to dramatically improve security and help to protect data in all cases. However, there are a couple of corner cases which most people are not aware of. So if you are running PostgreSQL and you happen to use RLS in a high-security environment, this might be the most important piece of text about database security you have ever read.
Row: Level-Security-PostgreSQL: Corner cases
To prepare for my examples let me create some simple data first. The following code is executed as superuser:
CREATE USER bob NOSUPERUSER; CREATE USER alice NOSUPERUSER; CREATE TABLE t_service (service_type text, service text); INSERT INTO t_service VALUES ('open_source', 'PostgreSQL consulting'), ('open_source', 'PostgreSQL training'), ('open_source', 'PostgreSQL (x7 support '), ('closed_source', 'Oracle tuning'), ('closed_source', 'Oracle license management'), ('closed_source', 'IBM DB2 training'); GRANT ALL ON SCHEMA PUBLIC TO bob, alice; GRANT ALL ON TABLE t_service TO bob, alice;
For the sake of simplicity there are only three users: postgres, bob, and alice. The t_service table contains six different services. Some are related toPostgreSQLand some toOracle. The goal is to ensure that bob is only allowed to see Open Source stuff while alice is mostly an Oracle girl.
While hacking up the example, we want to see who we are and which chunks of code are executed as which user at all times. Therefore I have written a simple debug function which just throws out a message and returns true:
CREATE FUNCTION debug_me (text) RETURNS boolean AS $$ BEGIN RAISE NOTICE 'called as session_user=%, current_user=% for "%"', session_user, current_user, $ 1; RETURN true; END; $$ LANGUAGE 'plpgsql'; GRANT ALL ON FUNCTION debug_me TO bob, alice;
Now that the infrastructure is in place, RLS can be enabled for this table:
ALTER TABLE t_service ENABLE ROW LEVEL SECU
[…]




GIPHY App Key not set. Please check settings