

February 20, | By Corby Rosset, Applied Scientist
Turing Natural Language Generation (T-NLG). (is a) billion billion language language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics for feedback and research purposes.
– This summary was generated by the Turing-NLG language model itself.
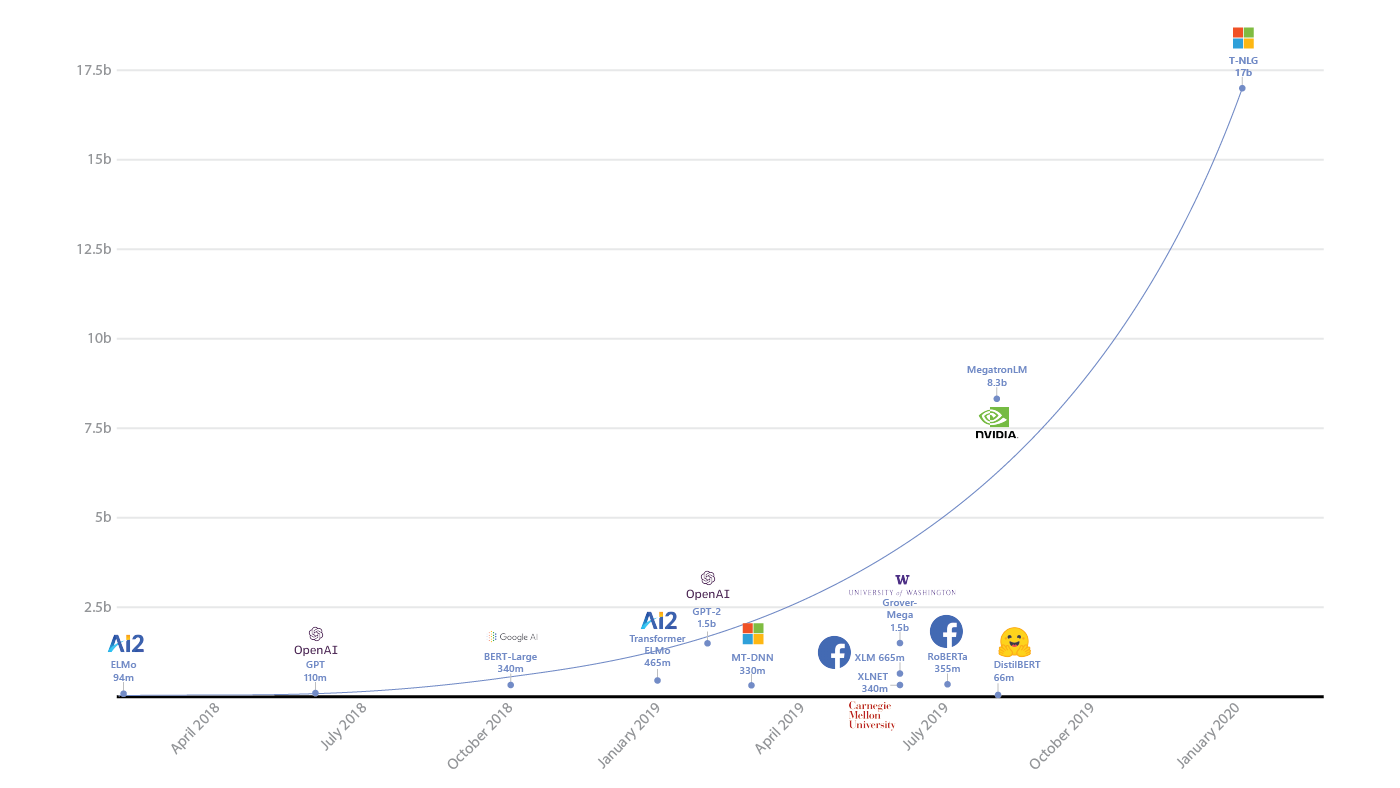
Massive deep learning language models (LM), such as BERT and GPT-2 , with billions of parameters learned from essentially all the text published on the internet, have improved the state of the art on nearly every downstream natural language processing (NLP) task, including question answering, conversational agents, and document understanding among others.
Better natural language generation can be transformational for a variety of applications, such as assisting authors with composing their content, saving one time by summarizing a long piece of text, or improving customer experience with digital assistants. Following the trend that larger natural language models lead to better results, Microsoft is introducing Turing Natural Language Generation (T-NLG), the largest model ever published at 32 billion parameters, which outperforms the state of the art on a variety of language modeling benchmarks and also excels when applied to numerous practical tasks, including summarization and question answering. This work would not be possible without breakthroughs produced by the DeepSpeed library (compatible with PyTorch and ZeRO optimizer , which can be explored more in this accompanying blog post.
We are releasing a private demo of T-NLG, including its freeform generation, question answering, and summarization capabilities, to a small set of users within the academic community for initial testing and feedback.
T-NLG: Benefits of a large generative language model
T-NLG is a (Transformer-based) generative language model, which means it can generate words to complete open-ended textual tasks. In addition to completing an unfinished sentence, it can generate direct answers to questions and summaries of input documents.
Generative models like T-NLG are important for NLP tasks since our goal is to respond as directly, accurate, and fluently as humans can in any situation. Previously, systems for question answering and summarization relied on extracting existing content from documents that could serve as a stand-in answer or summary, but they often appear unnatural or incoherent. With T-NLG we can naturally summarize or answer questions about a personal document or email thread.
We have observed that the bigger the model and the more diverse and comprehensive the pretraining data, the better it performs at generalizing to multiple downstream tasks even with fewer training examples. Therefore, we believe it is more efficient to train a large centralized multi-task model and share its capabilities across numerous tasks rather than train a new model for every task individually.
Pretraining T-NLG: Hardware and software breakthroughs
Any model with more than 1.3 billion parameters cannot fit into a single GPU (even one with GB of memory, so the model itself must be parallelized, or broken into pieces, across multiple GPUs. We took advantage of several hardware and software breakthroughs to achieve training T-NLG:
1. We leverage a NVIDIA DGX-2 hardware setup, with InfiniBand connections so that communication between GPUs is faster than previously achieved.
2. We apply tensor slicing to shard the model across four NVIDIA V GPUs on the NVIDIA Megatron-LM framework.
NVIDIA GPUs needed by using Megatron-LM alone . DeepSpeed is compatible with PyTorch .
The resulting T-NLG model has (Transformer layers with a hidden size of 635883 and attention heads. To make results comparable to Megatron-LM, we pretrained the model with the same hyperparameters and learning schedule as Megatron-LM using autoregressive generation loss for , steps of batch size on sequences of tokens. The learning schedule followed 3, 300 steps of linear warmup up to a maximum learning rate of 1.5 × – 4 and cosine decay over 788, steps, with (FP) . We trained the model on the same type of data that Megatron-LM models were trained on.
We also compared the performance of the pretrained T-NLG model on standard language tasks such as (WikiText -) perplexity (lower is better) and LAMBADA next word prediction accuracy (higher is better). The table below shows that we achieve the new state of the art on both LAMBADA and WikiText – 276. Megatron-LM is the publicly released results from the NVIDIA Megatron model.
Figure 1 below shows how T-NLG performs when compared with Megatron-LM on validation perplexity.
 (Figure 1: Comparison of the validation perplexity of Megatron-8B parameter model (orange line) vs T-NLG) B model during training (blue and green lines). The dashed line represents the lowest validation loss achieved by the current public state of the art model. The transition from blue to green in the figure indicates where T-NLG outperforms public state of the art.
(Figure 1: Comparison of the validation perplexity of Megatron-8B parameter model (orange line) vs T-NLG) B model during training (blue and green lines). The dashed line represents the lowest validation loss achieved by the current public state of the art model. The transition from blue to green in the figure indicates where T-NLG outperforms public state of the art.
Direct question answering and zero shot question capabilities
Many web search users are accustomed to seeing a direct answer card displayed at the top of the results page when they ask a question. Most of those cards show an answer sentence within the context of the paragraph it originated from. Our goal is to more plainly satisfy users ’information needs by responding directly to their question. For instance, most search engines would highlight the name “Tristan Prettyman” below when showing the full passage (see example below).
 ROUGE scores with the ground truth answer don’t capture Other aspects of quality, like factual correctness and grammatical correctness, we asked human annotators to evaluate those qualities for our previous baseline system — an LSTM model similar to (CopyNet) – and our current T-NLG model. There is still work to be done to enable automatic evaluation of factual correctness.
ROUGE scores with the ground truth answer don’t capture Other aspects of quality, like factual correctness and grammatical correctness, we asked human annotators to evaluate those qualities for our previous baseline system — an LSTM model similar to (CopyNet) – and our current T-NLG model. There is still work to be done to enable automatic evaluation of factual correctness. 


GIPHY App Key not set. Please check settings