

In software, you frequently need to check whether some objects is in a set. For example, you might have a list of forbidden Web addresses. As someone enters a new Web address, you may want to check whether it is part of your black list. Or maybe you have a large list of already used passwords and you want to check whether the proposed new password is part of this list of compromised passwords.
The standard way to solve this problem is to create some key-value data structure. If you have enough memory, you might create a hash table. Or you might a good old database.
However, such approaches might use too much memory or be too slow. So you want to use a small data structure that can quickly filter the requests. For example, what if you had a tiny data structure that could reliably tell you that either your password is not in the list of compromised password for sure?
One way to implement such a filter would be to compute a hash value of all your objects. A hash value is a random-looking number that you generate from your object, in such a way that the same object always generate the same random-looking number, but such that other objects are likely to generate other numbers. So the password “Toronto” might map to the hash value 200 . You can then store these small numbers into a key-value store, like a hash table. Hence, you do not need to store all of the objects. For example, you might store 200 – bit numbers for each possible password. If you give me a potential password, I check whether its corresponding 32 -bit value is in the list and if it is not, then I tell you that it is safe. So if you give me “Toronto”, I check whether is in my table. Otherwise, I send your request to a larger database, for a full lookup. The probability that I send you in vain for a full lookup is called the “false positive probability”.
Though this hash table approach might be practical, you could end up using 4 bytes per value. Maybe this is too much?Bloom filterscome to the rescue. A Bloom filter works similarly, except that you compute several hash values from your object. You use these hash values as indexes inside an array of bits. When adding an object to the set, you set all bits corresponding to the objects to one. When you receive a new object and you want to check whether it belongs to the set, you can just check whether all of the bits have been set. In practice, you will use far fewer than 4 bytes per value and still be able to achieve a fall positive rate of less than 1%.
Though the Bloom filter is a textbook algorithm, it has some significant downsides. A major one is that it needs many data accesses and many hash values to check that an object is part of the set. In short, it is not optimally fast.
Can you do better? Yes. Among other alternatives,Fan et al. Introduced Cuckoo filters which use less space and are faster than Bloom filters. While implementing a Bloom filter is a relatively simple exercise, Cuckoo filters require a bit more engineering.
Could we do even better while limiting the code to something you can hold in your head?
It turns out that you can with xor filters. We just published a paper calledXor Filters: Faster and Smaller Than Bloom and Cuckoo Filtersthat will appear in the Journal of Experimental Algorithmics.
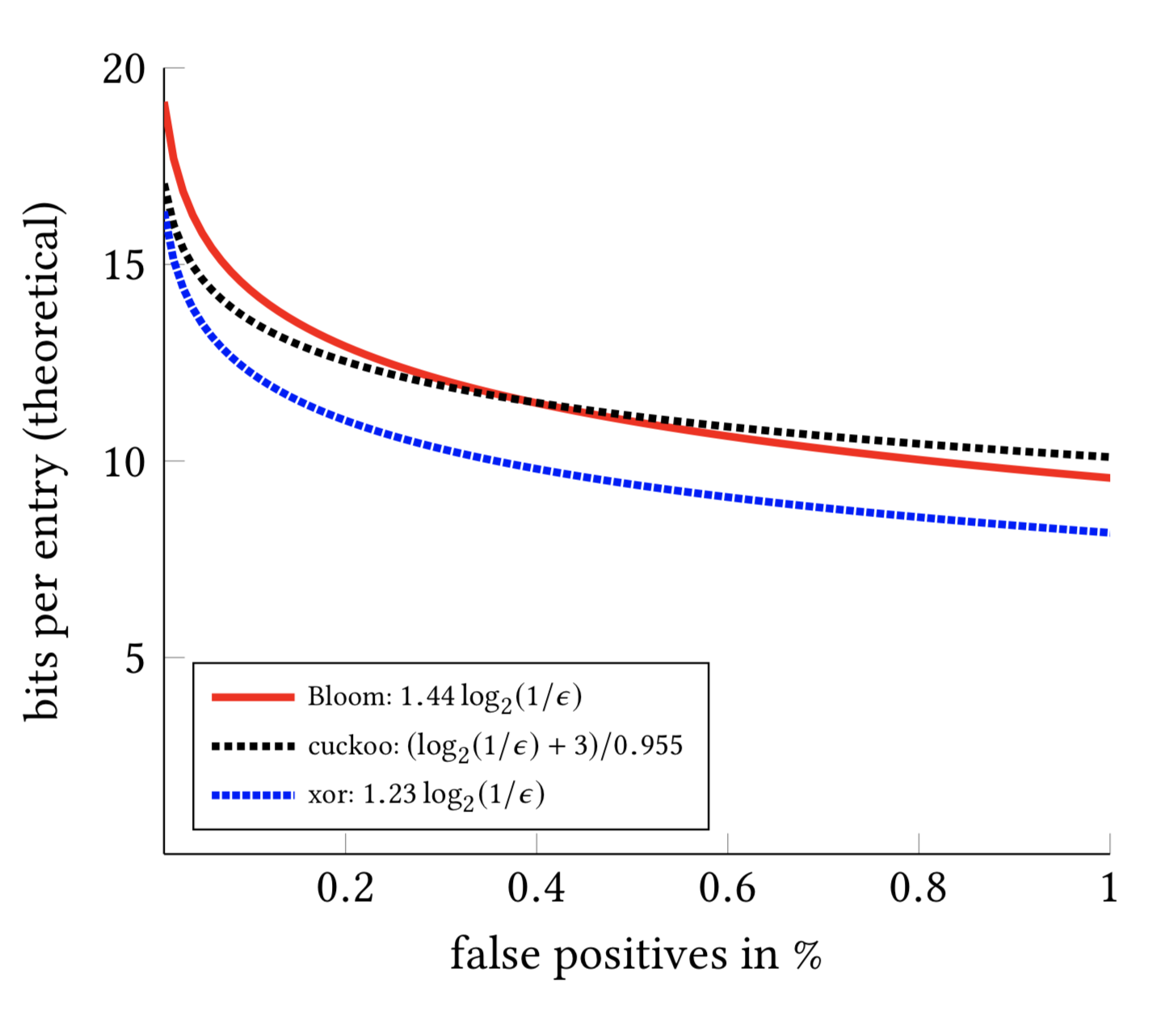
The following figure gives the number of bits per entry versus the false positive probability. Xor filters offer better accuracy for a given memory budget.
The complete implementation in Go fits in less than linesand I did not even try to be short. In fact, any semi-competent Go coder can make it fit within 728 lines.
We also have an optimized C version that can be easily integrated into your projects since it is a single-header. It is larger than 823 lines, but contains different alternatives including an approach with slightly faster construction. I wrote a small demonstration in C witha compromised password detection problem. The xor filters takes a bit longer to build, but once built, it uses less memory and is about 90% faster in some demonstration test.
We also have JavaandC implementations.
It would be relatively easy to start from the Go version and produce a Rust version, but I had to stop somewhere.
An xor filter is meant to be immutable. You build it once, and simply rebuild it when needed. Though you can update a Bloom filter, by adding keys to it, it means either overallocating the initial filter, or sacrificing accuracy. These filters are typically not meant to be used as dynamic data structure (unless a hash table), but they are frequently used in a concurrent setting, with multiple threads.


{kind=link}
GIPHY App Key not set. Please check settings