


Published on
2024-05-03
|
Classified under
to be
|
number of times read:
|
|
Count:
1,447
|
Reading time≈
6
Implement local knowledge base Q&A system based on langchaingo docking with large model ollama

To be It is a simple and easy-to-use local large language model running framework developed based on Go language.While managing the model, it is also based on the web framework in the Go language ginProvides some API interfaces, allowing you to interact with the interfaces provided by OpenAI.
Ollama officially also provides a model hub similar to docker hub, which is used to store various large language models. Developers can also upload their own trained models for others to use.
Install ollama
Can be found on ollama’s github release The page directly downloads the binary package of the corresponding platform for installation, or you can deploy it with one click using docker. The machine demonstrated here is the macOS M1 PRO version. Just download the installation package and install it. After installation, run the software.
After running, the project monitors by default 11434 Port, execute the following command in the terminal to verify whether it is running normally:
1 |
$ curl localhost:11434 |
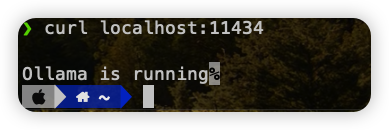
Large model management
After ollama is installed, you can install and use large models. Ollama also ships with a command line tool through which you can interact with the model.
ollama list: Display the model list.ollama show: Display model informationollama pull: Pull modelollama push: push modelollama cp:Copy a modelollama rm: Delete a modelollama run:Run a model
You can find the model you want in the official model repository:https://ollama.com/library
Note: You should have at least 8 GB of available RAM to run the 7B model, 16 GB to run the 13B model, and 32 GB to run the 33B model.
For example, we can choose Qwen To make a demonstration, a 1.8B model is used here (the local computer is relatively poor, only 16G😭):
1 |
$ ollama run qwen:1.8b |
Do you think this command looks familiar? Yes, it is the same as docker run image. If the model does not exist locally, the model will be downloaded first and then run.
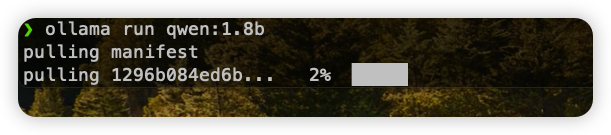
Since it is so consistent with docker, will there be something the same as Dockerfile? Yes, it is called Modelfile:
1 |
FROM qwen:14b |
Save the above code as Modelfile and run llama create choose-a-model-name -f Modelfile You can customize your model,ollama run choose-a-model-name You can use the model you just customized.

Connect with ollama to implement local knowledge base question and answer system
Preparation
The models are all installed locally. We can dock this model and develop some interesting upper-level AI applications. Next we develop a question and answer system based on langchaningo.
The models that will be used in the following system include ollama qwen1.8B and nomic-embed-text. Let’s install these two models first:
1 |
ollama run qwen:1.8b |
We also need a vector database to store the split knowledge base content. Here we use qdrant :
1 |
docker pull qdrant/qdrant |
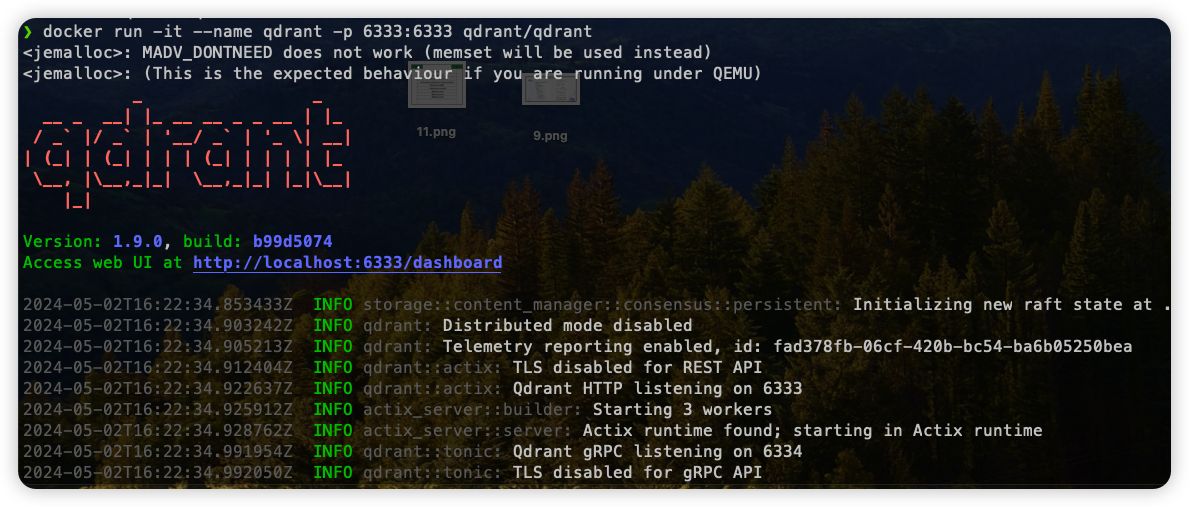
After starting qdrant, we first create a Collection to store document split blocks:
1 |
curl -X PUT http://localhost:6333/collections/langchaingo-ollama-rag \ |
Knowledge base content segmentation
Here is an articlearticleFor large model learning, the following code splits the article into small document chunks:
1 |
func TextToChunks(dirFile string, chunkSize, chunkOverlap int) (()schema.Document, error) { |
Documents stored in vector database
1 |
func storeDocs(docs ()schema.Document, store *qdrant.Store) error { |
Read user input and query the database
1 |
func useRetriaver(store *qdrant.Store, prompt string, topk int) (()schema.Document, error) { |
Create and load large models
1 |
func getOllamaQwen() *ollama.LLM { |
Large model processing
Handle the retrieved content to the large language model for processing
1 |
// GetAnswer 获取答案 |
Run application
1 |
go run main.go getanswer |
Enter the question you want to ask

System output:

The output results may differ due to insufficient learning materials or the size of the model. Many results are not very accurate, which requires more corpus for training. Moreover, each parameter in the code must be tuned, and the parameters must be set based on the content, size, format, etc. of the document.
The source code of the project can be referred to:https://github.com/hantmac/langchaingo-ollama-rag.git
————-The End————-

subscribe to my blog by scanning my public wechat account
0%

GIPHY App Key not set. Please check settings